Chapitre 1: Biochimie – Introduction et lipides
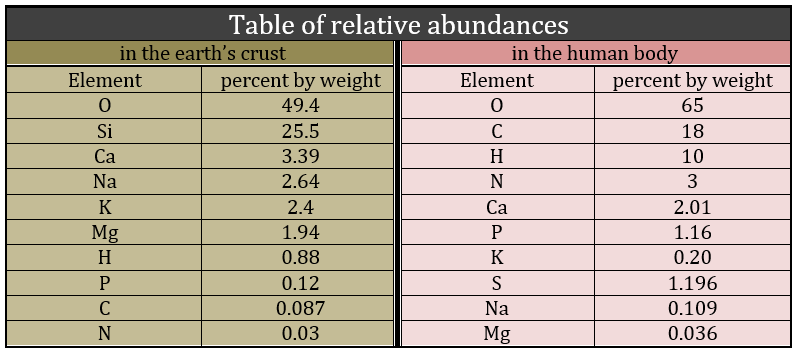
La biochimie est un domaine de la chimie lié aux corps vivants, animaux ou végétaux. Ce champ est loin de la chimie inorganique et une simple comparaison peut le montrer: la répartition des molécules dans la croûte terrestre et dans un corps vivant est totalement différente. Le premier est essentiellement composé de silice et le second de carbone.
Historiquement, la première théorie sur la vie était qu’elle est donnée par Dieu et seulement par Lui. Les molécules sont inanimées et ne peuvent pas être transformées en un corps vivant sauf si Dieu y insuffle la vie. C’est ce qu’on appelle la théorie du vitalisme.
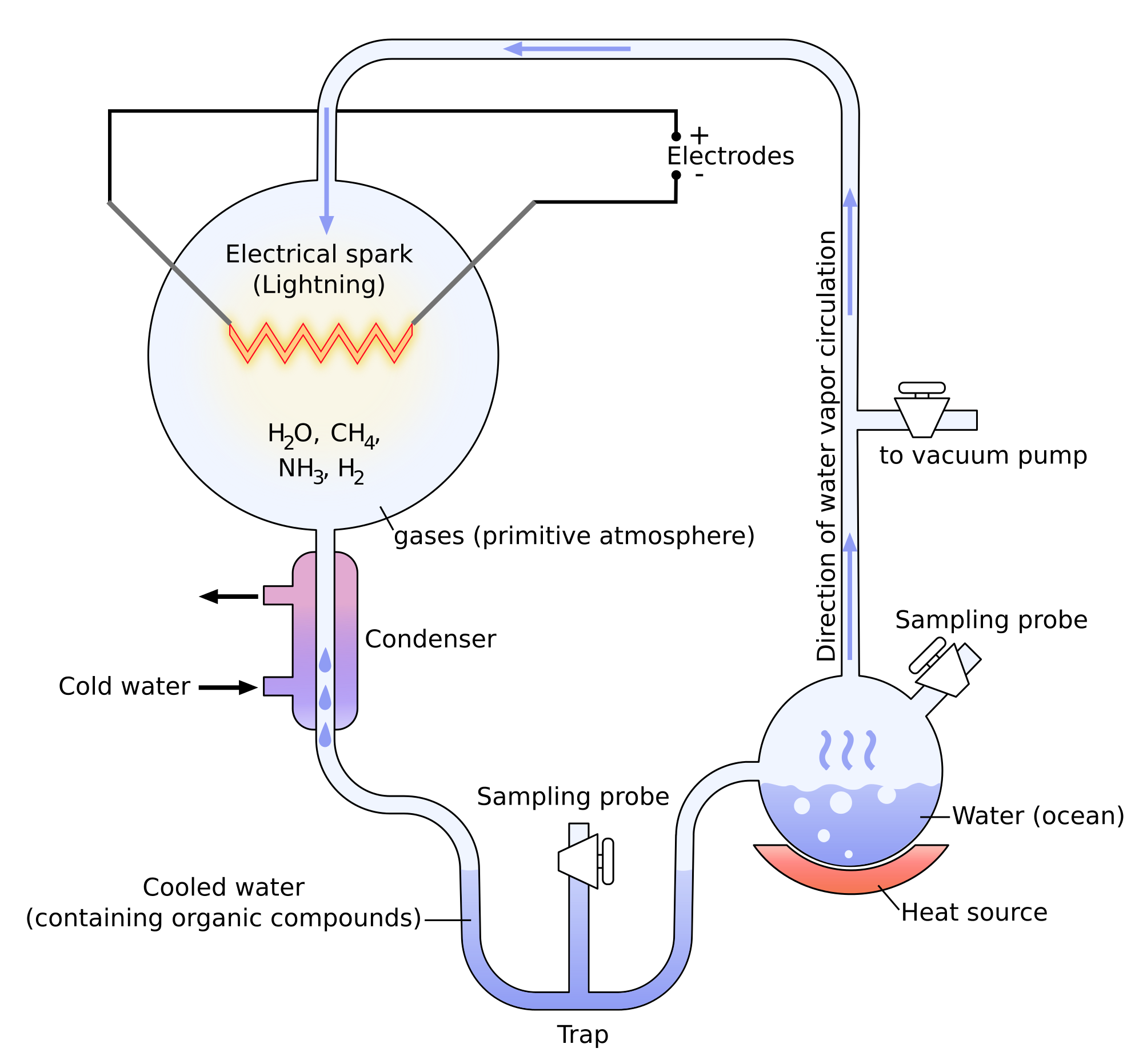
Miller a montré à travers ses expériences qu’il était possible de créer des molécules appartenant à des corps vivants avec des molécules simples. Les expériences de Miller consistent dans la modélisation des conditions sur Terre avant l’apparition de la vie. Il n’y avait pas beaucoup d’oxygène en ce moment et l’atmosphère était essentiellement composée d’ammoniac, de méthane, d’hydrogène et d’eau. La température était bien plus élevée et il y avait beaucoup d’éclairs. Dans ces conditions, certaines molécules présentes dans les organismes vivants se sont formées spontanément: urée, glycine, alanine, …
Pourtant, il n’y avait aucune trace de protéines et surtout d’ARN (acides ribonucléiques), les molécules capables d’écrire des molécules d’ADN (acides désoxyribonucléiques). Il a été montré plus tard que certaines molécules de météorites permettaient la formation d’ARN.
Principales caractéristiques de la biochimie
Les limitations
Parmi les bonnes centaines d’atomes du tableau de Mendeleev, on ne trouve que 16 liaisons différentes en biochimie mais elle permet la formation d’une infinité de molécules organiques. Ceci est d’autant plus surprenant que les réactions impliquées dans les processus biologiques sont limitées par les conditions biologiques de l’existence: il n’y a aucune manière qu’une réaction qui nécessite une température de 100 ° C ait lieu dans notre corps. Cela endommagerait les molécules environnantes et brûlerait les tissus. Comme toute réaction chimique, ils doivent obéir aux règles de la thermodynamique et trouver l’énergie nécessaire pour faire la réaction ailleurs.
La spécialisation
Dans un corps, les réactions sont faites dans des cellules et peuvent également être compartimentées à l’intérieur de la cellule. Toutes les cellules ne peuvent pas faire toutes les réactions et certaines cellules sont spécialisées. La spécialisation est écrite dans l’information génétique et se traduit par la présence ou l’absence de certaines enzymes. De plus, dans une cellule, il n’y a pas le même type de réactions dans les mitochondries que dans le réticulum endoplasmique. C’est parce que les réactions sont régulées, positivement ou négativement, par des catalyseurs.
Les Enzymes
La température doit rester basse (~ 37 ° C) et ne peut pas beaucoup varier. ΔG = ΔH-TΔS doit être négatif et proche de zéro. La vitesse de réaction serait proche de zéro sans catalyseur.
Il y a un système de régulation dans les cellules: l’activité des catalyseurs dépend des besoins de la cellule. Si la cellule est pleine d’une espèce D, il n’est pas nécessaire d’en accumuler davantage alors que les ressources pourraient être utilisées dans un processus différent. La présence de l’espèce D influencera un catalyseur (souvent une enzyme) qui agit sur une réaction conduisant à la formation de D. La présence de D peut inhiber une enzyme responsable de la réaction ou activer une enzyme inhibant la réaction. Au contraire, l’absence de D peut également être détectée par cette enzyme ou par une autre pour favoriser la formation de D.
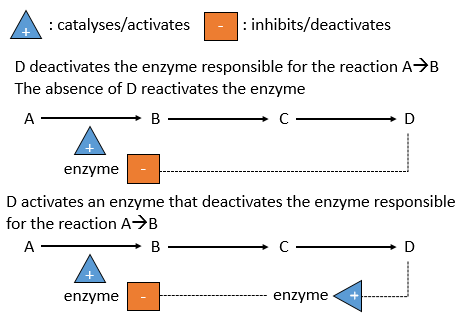
La gestion de l’énergie est un problème global pour le corps: les processus ne peuvent pas consommer ou rejeter trop de chaleur à la fois. Il pourrait endommager les cellules environnantes et inhiber la plupart des enzymes: la température du corps est habituellement dans la gamme optimale d’efficacité pour les enzymes et s’il y a une variation de température, l’activité des enzymes diminue de manière significative.
La régulation
De plus, il y a des périodes durant lesquelles nous consommons moins d’énergie (quand nous dormons par exemple) et des périodes où le corps a besoin de plus de ressources (en faisant du sport, en période de stress, …). Ces périodes ne coïncident pas avec les périodes pendant lesquelles nous produisons l’énergie (quand nous mangeons). Il doit donc y avoir un moyen efficace de stocker l’énergie quand elle est produite et de la libérer en cas de besoin. Cela se fait par la formation d’ATP (adénosine triphosphate) à partir d’ADP (adénosine diphosphate). Cette réaction n’est possible que dans les mitochondries mais l’énergie est nécessaire partout. L’énergie doit donc également être transportée dans les différents compartiments des cellules et dans le corps.
Ce cours se concentrera sur ces problèmes à travers l’exemple de la dégradation du glucose. Avant cela, nous allons faire une introduction des principaux types de molécules que nous trouvons le corps.
Les molécules du corps :
Ce cours se concentrera sur ces problèmes à travers l’exemple de la dégradation du glucose. Avant cela, nous allons faire une introduction des principaux types de molécules que nous trouvons le corps.
L’ eau
Notre corps est composé à 60-70% d’eau. La plupart des réactions sont ainsi réalisées dans des conditions aqueuses et polaires. L’eau implique une organisation entre les molécules. Dans la glace, une molécule d’eau forme des liaisons 4H avec d’autres molécules H2O.
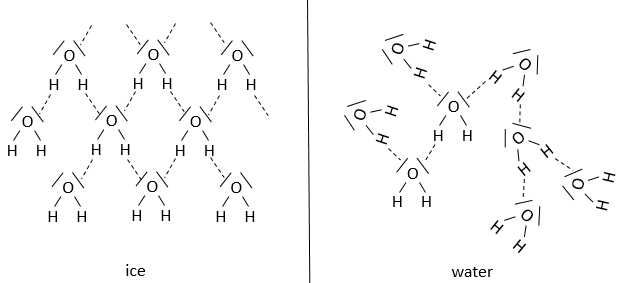
À la température du corps, ce nombre chute à environ 3,4. Les liaisons H se rompent facilement et fréquemment: leur énergie est de ~ 4,5 kcal / mol (contre ~ 110 kcal / mol pour une liaison covalente) et leur durée de vie est d’environ 10-9s.
Les liaisons H lient les molécules d’eau ensemble mais aussi la molécule d’eau à tout atome électronégatif (par exemple R-OH, R-CO-R, R-COOH, R-NH2 …). Les groupes qui forment des liaisons H sont appelés groupes hydrophiles. Les groupes qui ne permettent pas la formation de telles liaisons sont appelés groupes hydrophobes (une chaîne aliphatique par exemple, un phényle …). Les premières sont solubles dans l’eau alors que les secondes ne le sont pas (elles forment deux phases séparées). Une molécule qui porte des groupes hydrophiles et hydrophobes est appelée amphipathique.
La transpiration est un moyen que le corps a trouvé pour réguler la température: l’énergie de vaporisation de l’eau est de 540cal / g d’eau. Pour compenser la hausse de température de 1 degré, 2 grammes d’eau sont évaporés.
Les lipides :
Les lipides sont un groupe de molécules naturelles composées habituellement d’une tête hydrophile et d’une ou plusieurs chaînes hydrophobes.
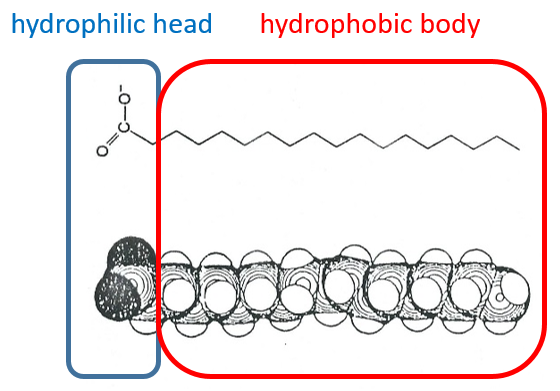
La présence de la tête polaire ne signifie pas que la molécule entière est soluble dans l’eau. Les chaînes hydrophobes sont insolubles dans l’eau et s’agrègent ensemble pour minimiser la surface de contact avec les molécules d’eau. Les principales fonctions biologiques des lipides comprennent le stockage d’énergie, la signalisation et l’action en tant que composants structuraux des membranes cellulaires. Les membranes qu’elles forment peuvent être soit une mono-couche (séparant une phase aqueuse et une phase organique) soit une bi-couche (séparant généralement deux phases aqueuses).
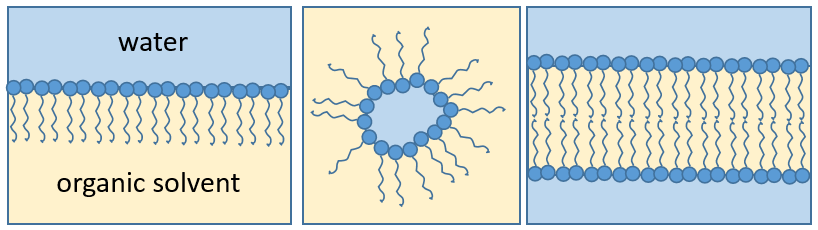
Les lipides sont triés en fonction de la capacité à former du savon. Pour ce faire, le lipide doit contenir un acide gras (une chaîne hydrophobe finissant par un groupe COOH hydrophile).
Leur nomenclature est terminée par ~ (an) oate. Par exemple, CH3(CH2)10COO– est appelé dodécanoate. Certains lipides portent des noms provenant du végétal dont ils proviennent. Par exemple CH3(CH2)14COO– est appelé palmitate car il provient de palmiers. S’il y a une double liaison dans la chaîne, sa position est indiquée au début du nom par un Δx où x est la position du premier carbone avec un C = C et le suffixe est maintenant ~ enoate. Par exemple, CH3(CH2)CH=CH(CH2)7COO–CH3 est appelé A9-hexadécénoate.
La présence d’une double liaison durcit la structure du lipide. Un lipide sans C = C est dit saturé et toutes les liaisons peuvent tourner. Ces lipides sont très flexibles. D’autre part, les C = C fixent la conformation localement car la double liaison ne peut pas tourner. En conséquence, la cohésion entre les chaînes est plus complexe et le nombre d’interactions de van der Waals diminue (en d’autres termes, les chaînes ne peuvent pas s’imbiber aussi bien que les chaînes saturées). Un lipide à double liaison est appelé insaturé. S’il y a plusieurs C = C, on parle de polyinsaturés. Pour illustrer la différence que fait un C = C, le tableau suivant montre une série de lipides avec leur température de fusion.
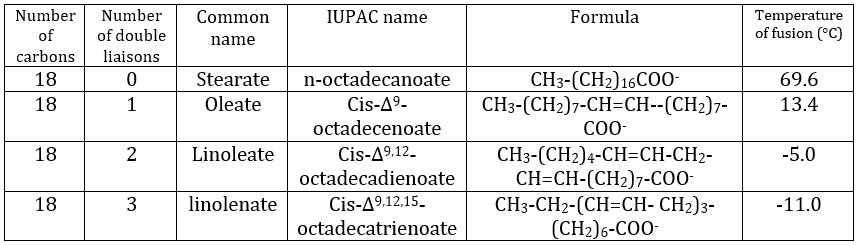
Les lipides insaturés se trouvent sous la forme d’une huile tandis que les lipides saturés se présentent sous la forme de graisses. Il est possible d’hydrogéner les lipides insaturés pour éliminer le C = C.
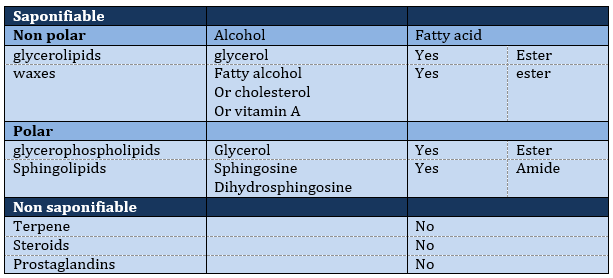
Lipides saponifiables
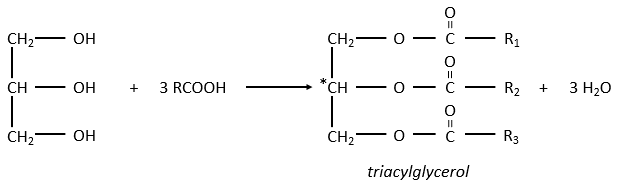
Le glycérol est un polyalcool avec 3 groupes -OH sur une chaîne à 3 carbones. Quand il réagit avec 3 équivalents de RCOO- (un lipide), il forme un triacylglycérol. Le carbone noté * C est chiral si R1 et R2 sont différents. La réaction dans la direction opposée est la réaction de saponification:
La réaction dans la direction opposée est la réaction de saponification:
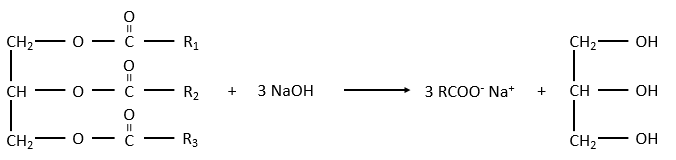
RCOONa est un savon. Le principe est assez simple: le savon forme des micelles autour de la saleté qui n’est pas soluble dans l’eau. Les chaînes hydrophobes encerclent la saleté et les têtes hydrophiles sont en contact avec l’eau.
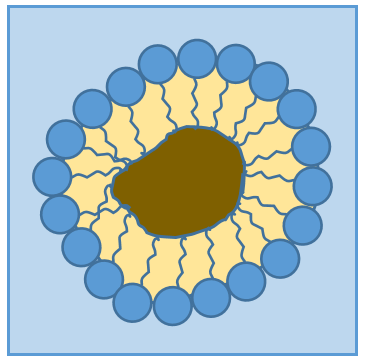
The whole thing is soluble in the water. Lipids are an energetic reservoir stocked under the form of pellets of fat in cells called adipocytes.
Waxes are a combination of a fatty acid with a fatty alcohol.
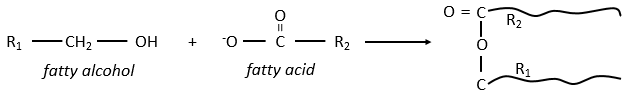
Ils sont très hydrophobes et constituent une protection efficace contre l’humidité (exemple: la laine de mouton) ou pour empêcher l’eau de s’évaporer (ex: plantes tropicales, cactus). Les baleines à dents utilisent un mélange de cires et de triacylglycérol, appelé spermaceti pour nager sans effort dans les profondeurs. A 37 ° C, le mélange est une huile mais la température baisse et le mélange cristallise. Sa densité augmente, ce qui permet au cachalot de flotter à cette profondeur.
Les lipides polaires présentent souvent un phosphate ou une amine chargée
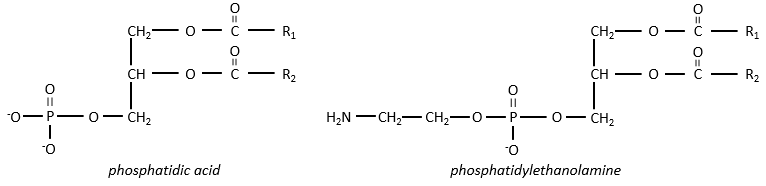
Il y a beaucoup de dérivés de l’acide phosphatidique. Notons l’acide phosphatidique R,

Beaucoup d’entre eux constituent les membranes de la cellule. Les sucres peuvent également être liées aux lipides par liaison ester et servir, dans ce cas, d’élément de signalisation.
Les sphingolipides sont des dérivés de la sphingosine et de la dihydrosphingosine.
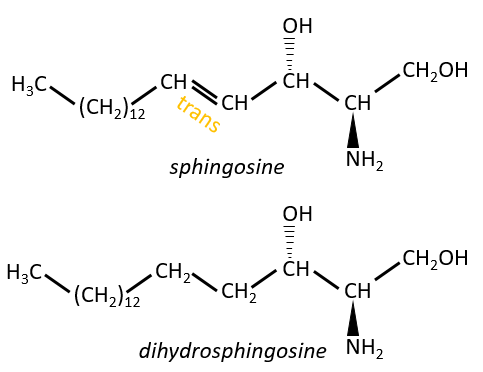
Les lipides sont liés par une liaison amide.
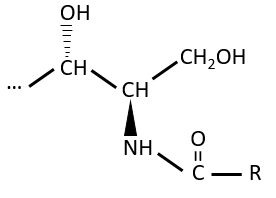
Les éléments donnant des propriétés différentes à la molécule peuvent se lier à l’alcool. Par exemple, une choline peut se lier à l’aide d’une liaison phosphodiester.
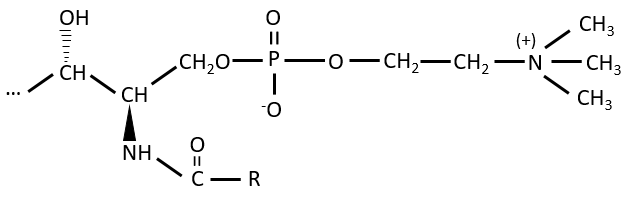
Cette molécule est une sphingomyéline et se trouve dans la membrane qui entoure certains axones des cellules nerveuses. Sur l’ester, un ucre peut être lié. Ces molécules sont appelées glycosphingolipides neutres ou cérébrosides parce qu’elles se trouvent souvent dans les membranes du cerveau. Encore une fois, le sucre est un élément de reconnaissance / signalisation.
Le sucre peut aussi être acide (par exemple un acide sialique) et alors la molécule est un glycosphingolipide acide, servant habituellement de récepteur.
Lipides non saponifiables
Terpènes
Ce sont de petites molécules dérivant de l’isoprène.
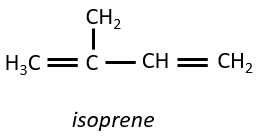
Les plus petits terpènes sont les monoterpènes, résultant de la combinaison de deux isoprènes.
8 équivalents de l’isoprène forment le bêta-carothène. Cette molécule de 40 carbones est un antioxydant qui protège des radicaux libres: elle est facilement excitée car les électrons peuvent être délocalisés.
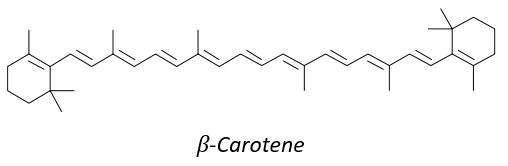
C’est aussi un précurseur de la vitamine A. C’est un groupe de composés organiques nutritionnels insaturés (trouvés dans les carottes, entre autres) qui comprend le rétinol, le rétinal, l’acide rétinoïque et plusieurs caroténoïdes de provitamine A (notamment le bêta-carotène).
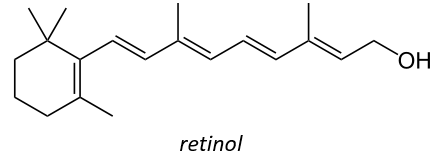
La vitamine A a de multiples fonctions: elle est importante pour la croissance et le développement, pour le maintien du système immunitaire et pour une bonne vision. La rétine de l’œil a besoin de vitamine A sous forme de rétinal, qui se combine avec la protéine opsine pour former la rhodopsine, la molécule absorbant la lumière nécessaire à la fois à la vision faible (vision scotopique) et à la vision des couleurs.
Il y a deux types de capteurs dans l’œil: les cônes et les bâtonnets. Le premier détecte les couleurs et les secondes la lumière. Les bâtonnets sont composées d’une série de disques bilipidiques avec des récepteurs de rhodopsine. Entre les hélices d’opsin est le 11-cis-rétinal
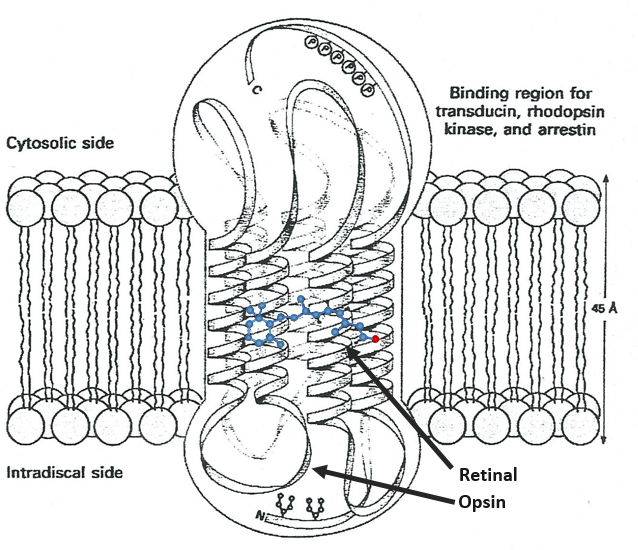
Toutes les liaisons sauf une dans la rétinal sont trans. Quand un photon frappe le rétinal, cette liaison devient trans, perturbant la molécule, puis les hélices protéiques qui transfèrent le signal nerveux. Un photon est suffisant pour générer un signal.
Dans les cônes, il y a des modifications spécifiques dans la structure de la protéine et le photon doit être dans une plage spécifique de longueur d’onde (c’est-à-dire une couleur) pour transférer le signal.
Les stéroïdes :
La base des stéroïdes est le stérol, une molécule faite de trois cycles de 6 C et un de 5 C.
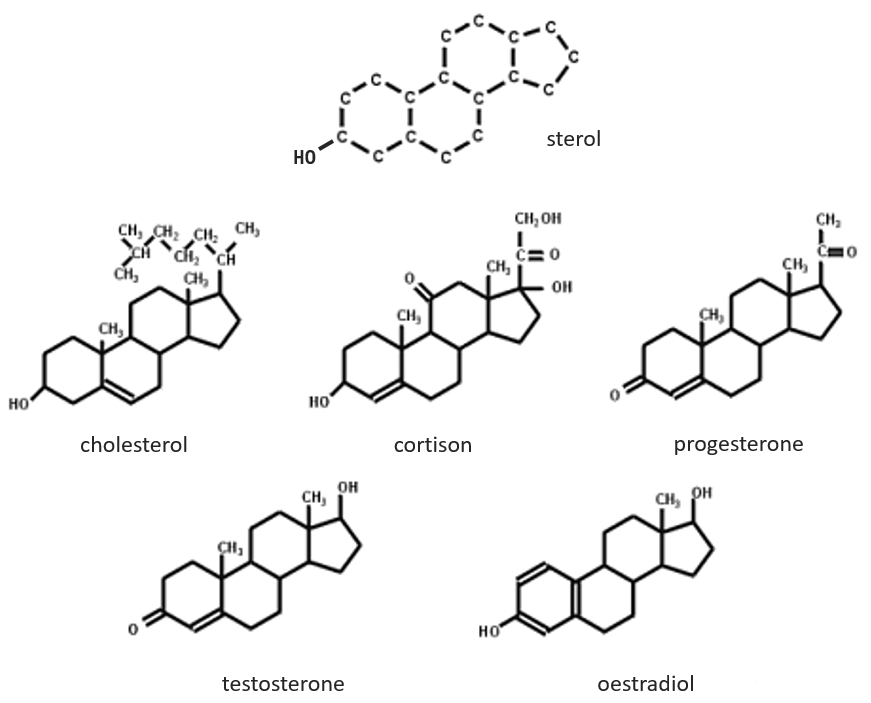
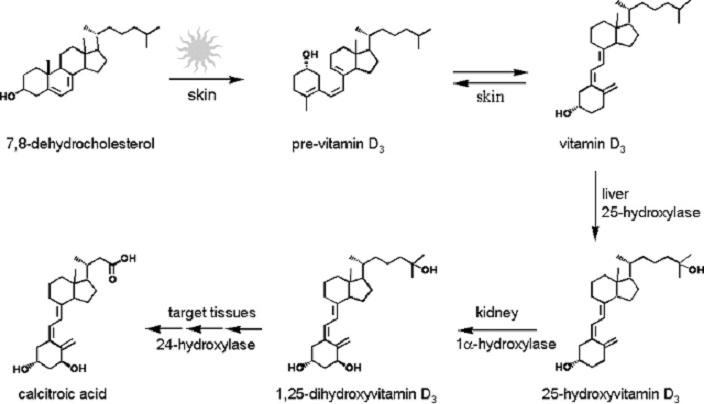
Le cholestérol est complètement hydrophobe. C’est un précurseur de plusieurs hormones, de la vitamine D et du sel biliaire.
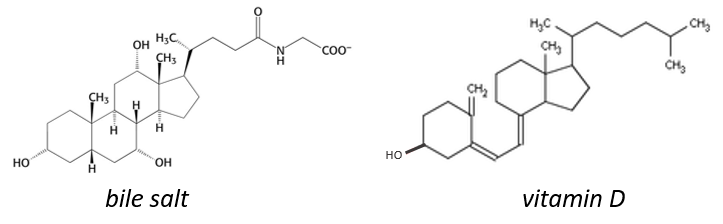
On entend souvent parler du bon et du mauvais cholestérol. C’est en fait une locution incorrecte. Le mode de transport du cholestérol est en fait le principe important. Le cholestérol est transporté par les lipoprotéines (une combinaison de lipides et de protéines) appelées LDL et HDL (pour les lipoprotéines de basse et haute densité). Le LDL transporte le cholestérol du foie vers le corps. Il est lié à certains récepteurs spécifiques sur LDL. Le rôle du HDL est de ramener le cholestérol inutilisé au foie où il est détruit. Il y a donc un équilibre entre le cholestérol qui quitte le foie et qui revient au foie.
Les prostaglandines :
Ce sont des hormones agissant sur une courte distance, avec une durée de vie courte et elles sont toutes fabriquées à partir de l’arachidonate, un lipide de la membrane cellulaire, par une phospholipase. Les prostaglandines activent de nombreux récepteurs membranaires.
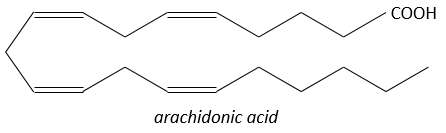
A la suite d’un stimulus donné, certains agents sont activés pour activer la PLA2 (phospholipase A2)PLA2. La PLA2 clive les phospholipides de la membrane pour obtenir des acides gras. A partir d’un acide gras 4 types de prostaglandines sont formés:
1) prostacycline: ils se trouvent dans la paroi des vaisseaux sanguins et empêchent la coagulation.
2) PGE et PGF (Prostaglandines E et F): elles sont responsables du cycle du sommeil et des contractions à l’accouchement.
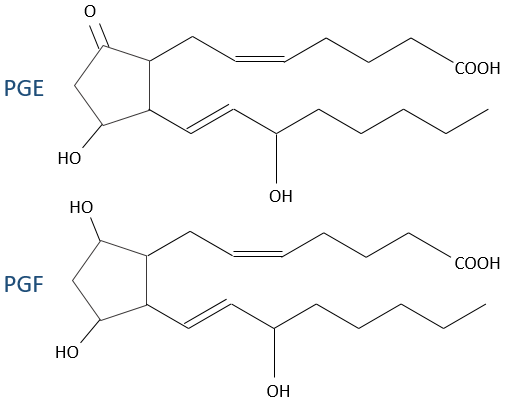
- thromboxane: ils sont impliqués dans le processus de coagulation.

- leucotriènes: nous les trouvons dans la paroi des poumons. Les asthmatiques ont une surproduction de leucotriènes.
L’aspirine bloque l’activité/production de la cyclo-oxygénase qui est une enzyme responsable de la formation des quatre types de prostaglandines à partir de l’arachidonate. La cortisone bloque la PLA2.
Fonction principale des lipides: constituant des membranes
Les membranes des cellules séparent l’intérieur de l’extérieur des cellules. Les deux côtés sont aqueux mais l’intérieur de la membrane est hydrophobe. Les membranes bilipidiques se forment spontanément (appelées liposomes). Les membranes sont composées de lipides et de protéines dont la composition dépend de la cellule: essentiellement, les protéines permettent les échanges et les transports d’un côté de la membrane à l’autre tandis que les lipides sont la paroi en béton de la membrane. Le cholestérol se place dans la partie hydrophobe de la membrane pour la consolider.
Chapitre 2: Les glucides
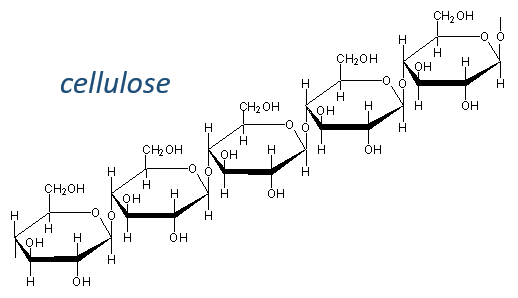
Les glucides sont essentiellement des hydrates cycliques de carbone (CN (H2O) N) mais peuvent aussi porter N, S, P. Les cycles ont habituellement une longueur de 5 ou 6 atomes et forment des macromolécules lorsque les cycles se lient. Un exemple est la cellulose, qui est présente dans les parois des légumes. En tant qu’êtres humains, nous ne digérons pas correctement la cellulose contenue dans les salades que nous mangeons, nous devons donc la mastiquer davantage pour la casser. Un autre exemple est la chitine qui est l’élément essentiel de la coquille des insectes, des crabes, etc.Types de sondes d’hybridation
La nomenclature des monocycles (ou des monomères dans lesquels nous considérons les macromolécules comme des polymères) est de terminer leur nom par ~ monosaccharide. Les plus connus sont le glucose et le fructose, qui diffèrent par la présence d’une cétone dans le fructose. Le glucose est le monosaccharide le plus abondant et représente 50% des carbones sur Terre. Les algues produisent des milliards de monosaccharides par année et nécessitent la lumière du soleil pour le faire. Dans l’industrie, nous utilisons des monosaccharides dans le papier, le coton, les boissons, la nourriture, les produits pharmaceutiques, …
Les tableaux suivants montrent les projections de Fischer des sucres. Fondamentalement, les chaînes sont composées de carbones portant des fonctions -OH. A l’extrémité supérieure, il y a un aldéhyde dans le cas des aldoses et une cétone dans le cas des cétoses. C’est le premier paramètre de tri. Le deuxième paramètre est la longueur de la chaîne, allant de 3 à 8 (les chaînes de 8 atomes de carbone sont fabriquées artificiellement).
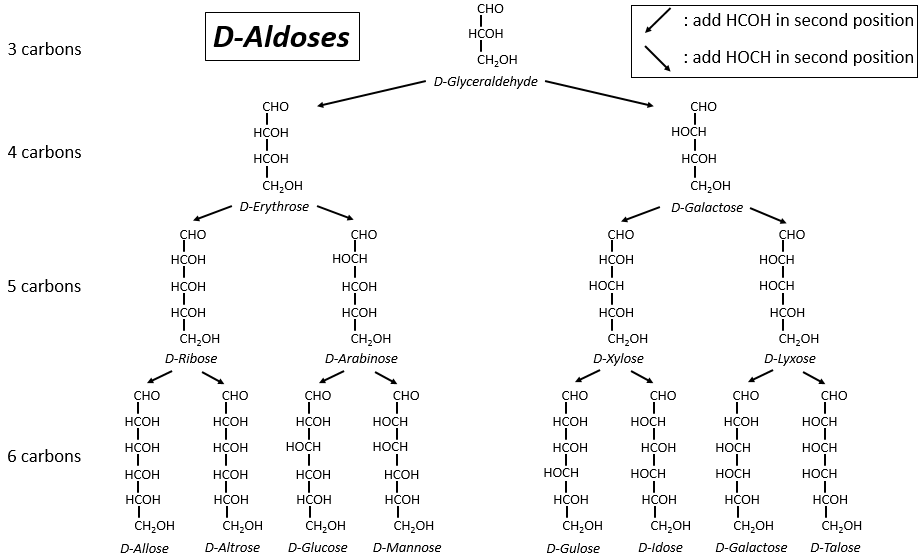
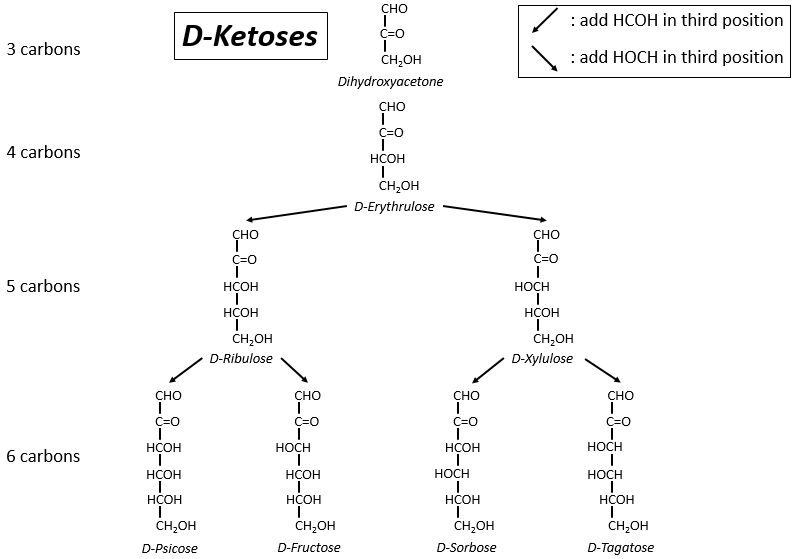
On a pu voir que les -OH ne sont pas tous du même côté de la chaîne. Les carbones à l’intérieur de la chaîne (pas ceux aux extrémités) sont chiraux et les sucres ont donc une activité optique. Les tableaux que nous avons montrés précédemment ne montrent que les molécules de dextrogyre, notées avec le préfixe D-, c’est-à-dire celles qui dévient la lumière vers la droite. La distinction n’est pas seulement importante pour la lumière: la plupart des enzymes n’acceptent qu’un seul des conformères, L (levogyre) ou D (dextrogyre).
Maintenant vous me direz que j’ai commencé cette section en disant que les glucides sont cycliques et que je n’ai montré que des molécules linéaires. Dans des conditions aqueuses, l’aldéhyde et une fonction hydroxyle (en position 4 ou 5) fusionnent pour former un hémiacétal, un cycle de 5 (cycles de furanose) ou 6 atomes (cycles de pyranose).
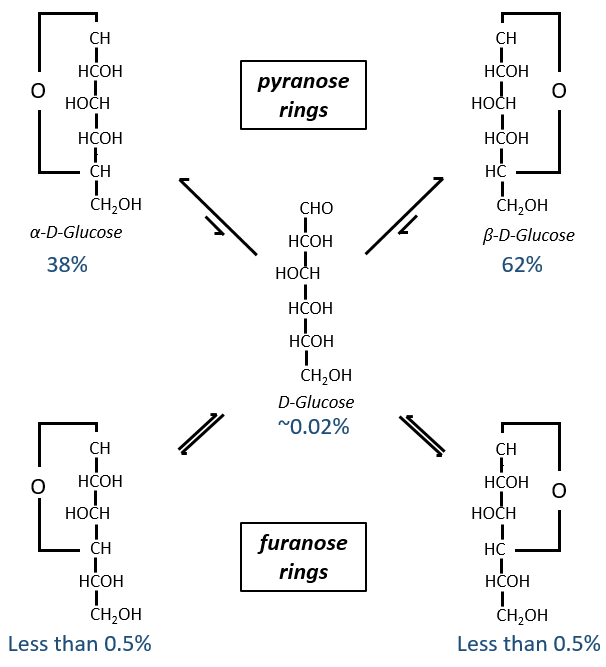
The equilibrium of this process is almost towards the cyclic forms with 6 atoms, i.e. the pyranose rings. The crystals of the linear sugars were obtained in pyridine in which the rotatory power is +19° for the glucose and in the water it was +53°.
This rotatory power is the averaged value of the species in the water (the α-D-glucose has [α]D=120 and the β-D-glucose has [α]D=19).
Projection of Haworth
The cycle is represented flat. The heterocyclic oxygen is on the top right position and the chain outside of the cycle is on top left position of the cycle. The –OH groups are placed on top of the cycle if they are on the left in the projection of Fischer and under the cycle if they are on the right of the chain in the projection of Fischer.
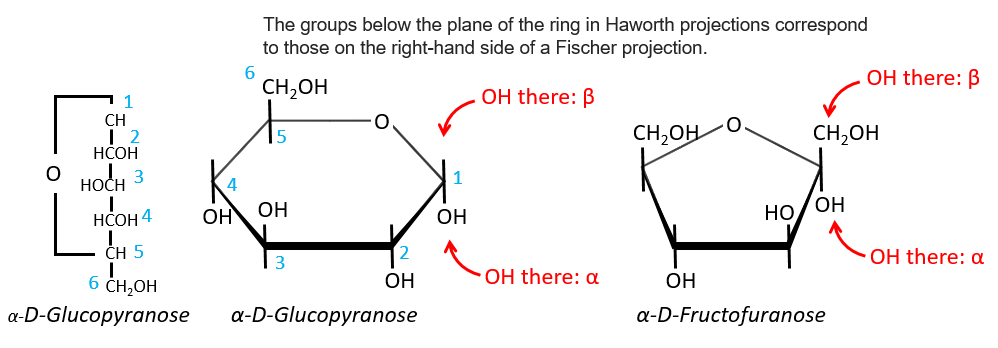
We enumerate the carbons starting from the right and moving in the clockwise direction. The C1 is the highest carbon of the Fischer projection and is here an anomeric carbon: when the glucose was put in water, the OH group could be on the left or right of the chain. Its position determines if the cycle is α or β and we can pass from the α to the β forms only by the linear form. We have the same kind of representation for furanose rings and the cyclisation is also done in the case of ketoses and of pentoses. Also note that the C1 carbon may be out of the cycle, as it is the case for the α-D-fructofuranose shown above.
Osides are monosaccharides bound to one molecule on the anomeric spot. The presence of this molecule there blocks the configuration of the monosaccharide: it cannot change from α to β or change for its linear form anymore. As the anomeric carbon is not available, the reduction power of the monosaccharide is also lost.
Disaccharides
They are combinations of two monosaccharides. We will use them to show where the liaisons can be and how we represent those molecules in the representation of Haworth.
- Maltose
It is the combination of two glucoses bound together in (1→4).
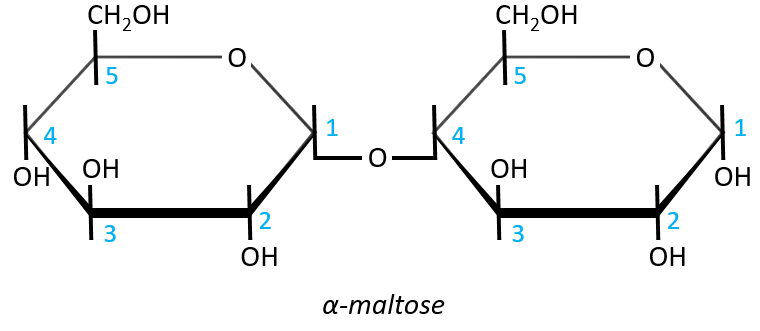
The liaison is made between the C1 of the glucose of the left and the C4 of the glucose of the right, indicated by (1→4). We let the representation of both glucoses as they were for the monosaccharides alone and bind them with a straight line. It is as simple as that. One anomeric carbon is taken by the liaison but the second is free. The molecule is thus a reductant and able to do the mutarotation.
The nomenclature of the α-maltose is
α-D-Glucopyranosyl-(1→4)-D-glucose
or also
4-O-α-D-Glucopyranosyl-D-glucose
The monosaccharide with its anomeric carbon free ends the name while the other monosaccharide name is ended by ~osyl. The position of the liaison between the monosaccharides is indicated by the (1→4) written between the monosaccharides or the 4-O prefix: liaisons between monosaccharides are always involving C1 so we just indicate the second carbon involved in the liaison (C4) and the fact that the liaison involves and oxygen atom. The alpha also gives an information on the liaison between the sugars: the type of the anomeric carbon that is now bound to the second monosaccharide. The dextro or levogyre character of each monosaccharide is indicated as well.
- Lactose
It is the combination of one β-galactose with one α-glucose. The liaison is also in (1→4).
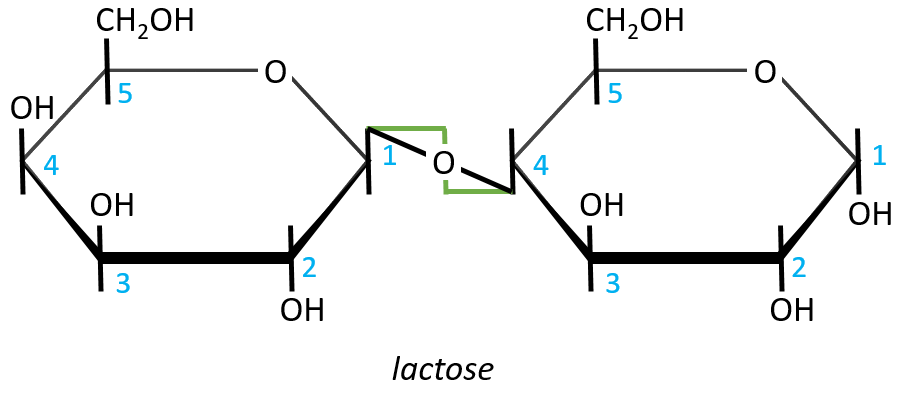
In this representation, we maintain both representations of the monosaccharides. The liaison between them is thus represented as a diagonal or as a S shaped line as showed above in green. The nomenclature is
β-D-galactopyranosyl-(1→4)-D-glucose
or
4-O-β-D-galactopyranosyl-D-glucose
- Sucrose (or saccharose)
It is an example of disaccharide for which the liaison is not 1à4. The saccharose is the combination of a α-glucose with a β-fructose. They are bond by their anomeric carbons, i.e. in (1→2).
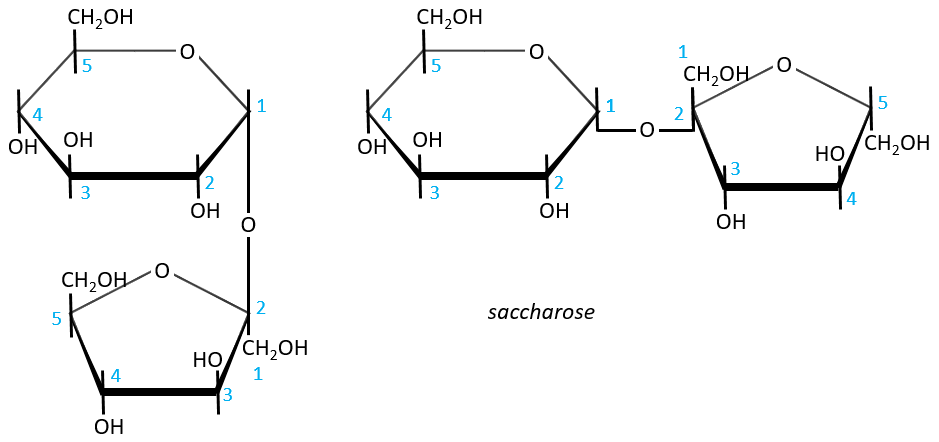
There is thus no possibility of mutarotation. The nomenclature is α-D-glucopyranosyl-(1→2)-β-D-fructofuranoside. The name doesn’t end by ose because the anomeric carbon is not free.
The invertase is an enzyme that is able to cleave the liaison between those two monosaccharides. This enzyme is interesting for the industry because the saccharose has a sweetening power way smaller than the sum of the sweetening powers of the fructose and of the glucose.
Polysaccharides
They are chains of monosaccharides. We can sort them in two types: homopolyosides that are chains of one single monosaccharide that is repeated, and heteropolyosides that are (usually) two different monosaccharides that are repeated with a given order or at random. The size of the chain can be very long (thousands to hundreds of thousands of monosaccharides).
Starch is one macromolecule we find in vegetables, composed of monosaccharides. There are separated in two groups: the amylose (15-20%) and the amylopectin (80-85%). The amylose is a chain of glucoses linked in (1→4) 100 to 300 units long while the amylopectin has ramifications every 30 sugars approximatively, linked in (1→6). In animals, the equivalent of the amylopectin is the glycogen for which the ramifications are more frequent (every 8 to 12 sugar). The amylose forms a α helix (6 to 8 glucoses form one whorl).
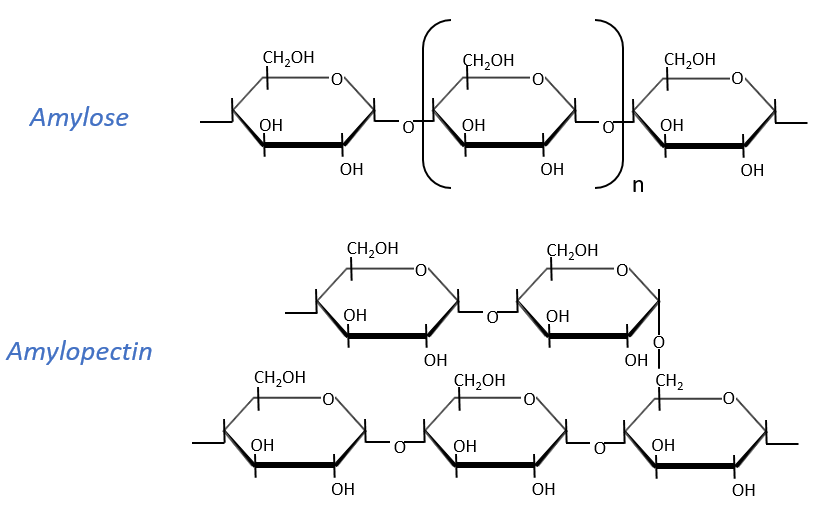
Enzymes can cleave liaisons to free glucose molecules. Some enzymes cleave in the chains (endoglycosidases), some at their extremities (exoglycosidases). Given the size of the starch and the amount of extremities, several enzymes can act simultaneously.
The cellulose is made of β-glucoses, up to 10000 units. This difference with the amylose leads to a huge difference of conformation: instead of helixes, the cellulose forms planes bound together by H bonds. Moreover, the β liaisons cannot be cleaved by the enzymes of most of the animals. Only ruminants are able to do it because they have cellulases, enzymes able to cleave the cellulose.
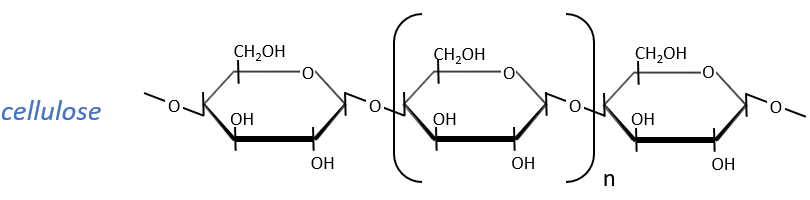
The chitin is similar to the cellulose except that the beta glucoses are replaced by a variant (N-acetylglucosamine). Combined to Ca2CO3 it forms exoskeletons of insects.
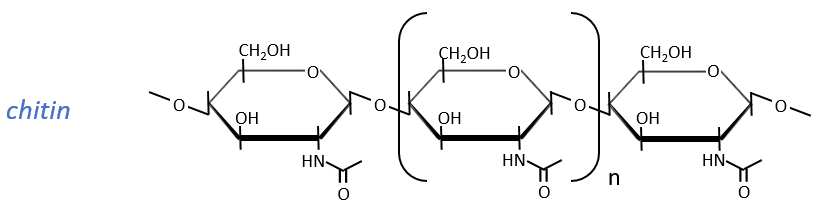
Heteropolyosides
Glycosaminoglycan
They are found at the outside of the cells, bound to the lipid bilayer and allow the movements of the cell (one motor is in the lipid bilayer). An example is the hyaluronic acid (the cosmetics industrials highlight it nowadays).
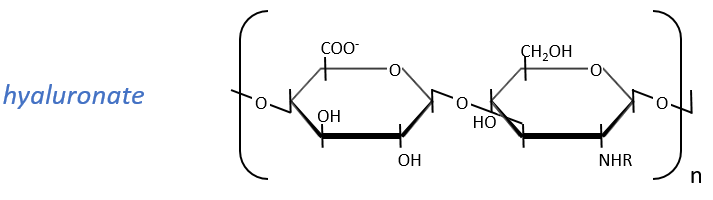
This molecule is a polymer composed of a repetition of a block of two monosaccharides, the β-glucoronate and one N-acetylglucosamine. They are bound in (1→4) and in (1→3) to form one chain. As the β-glucoronate is negatively charged, the chains don’t interfere one with each other. Chains are bound to proteins
Peptidoglycans
Some monosaccharides of the chain wear a peptide chain of amino acids. The peptide chains bind together to form a network with a given rigidity. Peptidoglycans are also known as the murein.
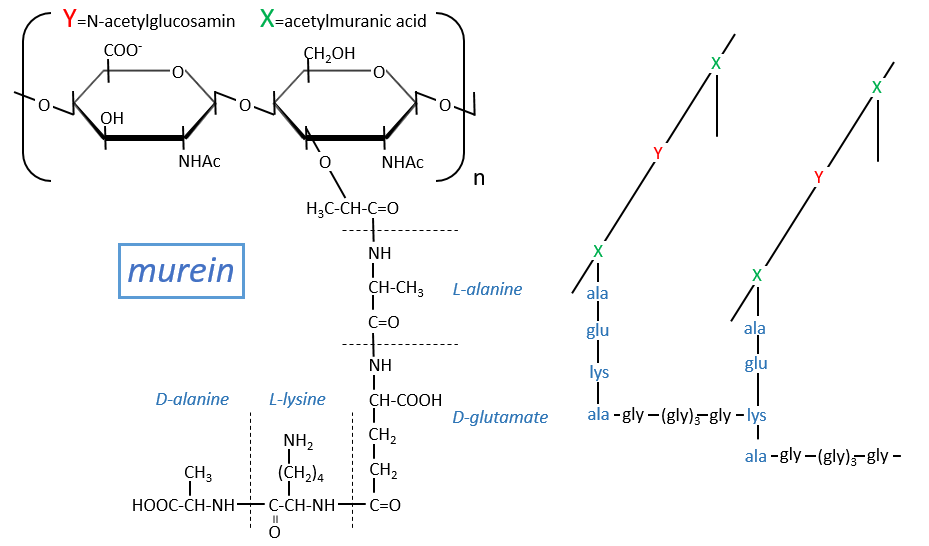
It is the rigid constituent of the membrane of bacteria’s. It is composed of a block of N-acetylglucosyl (a derivative of the glucose) bound in (1→4) with the N-acetylmuranic acid, the same monosaccharide but wearing one peptide chain on C3. The chain is bound to another chain by a liaison between several glycine’s and lysine to form a dense network. The peptides in the chains are consecutively L, D, L, D, …
The mechanism of some antibiotics is to break the liaison between the monosaccharides to destroy the whole structure.
Chapitre 3: Protéines et acides aminés
Le mot protéine vient du mot grec proteos, qui signifie premier. Les protéines sont en effet un élément essentiel de la vie. Elles sont bien définies dans la composition, la taille et la forme et chacune a un rôle très précis: transport, défense, hormones, … Certaines ont aussi un rôle exotique. Par exemple, certaines protéines empêchent le sang des poissons de geler. Nous pouvons cependant trier les protéines en trois classes principales: les protéines fibreuses, globulaires et membranaires. Les protéines fibreuses sont étirées et fragiles. Deux exemples sont la kératine et le collagène. La kératine est une protéine structurelle fibreuse dure et insoluble qui compose les cheveux, la laine, les cornes, les ongles, les griffes, etc. La ténacité de la kératine est rivalisée seulement par la chitine dans les matériaux biologiques. Ils ne sont pas seulement localisés dans les parties dures des animaux mais se trouvent dans toutes les cellules épithéliales, c’est-à-dire les cellules qui recouvrent les surfaces externes des organismes et les surfaces internes des organes pour renforcer leur structure. Les cornes, les griffes, les ongles … sont produits par des cellules épithéliales adaptées qui ont une quantité abondante de kératine durant leur croissance et après leur mort laissent la kératine pour aider à former une structure précieuse pour l’animal entier. Le collagène est la principale protéine structurelle dans l’espace extracellulaire, ce qui en fait la protéine la plus abondante chez les mammifères. Ils forment des os, des tendons, des cartilages en fonction du degré local de minéralisation. Les protéines membranaires se trouvent dans les membranes et servent de récepteurs ou fournissent des canaux pour transporter des ions ou des molécules d’un côté de la membrane à l’autre. Les protéines globulaires sont essentiellement des protéines non fibreuses et ont des fonctions diverses (exemple: hémoglobine, lysozyme). Toutes les enzymes sont des protéines globulaires.
Un point commun entre toutes les protéines est qu’elles sont insolubles dans les solvants organiques. Grâce à cela, nous avons pu déterminer leur structure (cristalline) et leur composition. Par exemple, dans les os, nous avons trouvé le collagène par cristallisation. Nous pouvons détruire la protéine pour déterminer les acides aminés dont elle est faite: glycol. Dans la soie, nous avons découvert la fibroïne, composée de sérine.
Les acides aminés (AA)
La structure générale des acides aminés est :
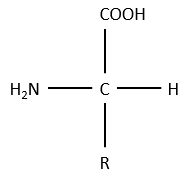
où R est le groupe qui fait la distinction entre tous les différents acides aminés (à une exception près). Ce sont des zwitterions: ils portent un groupe acide (COOH) et un groupe basique (NH2). Le carbone central est chiral et l’AA peut être L ou D. 20 AA sont présents dans les protéines (plus de 23 AA).
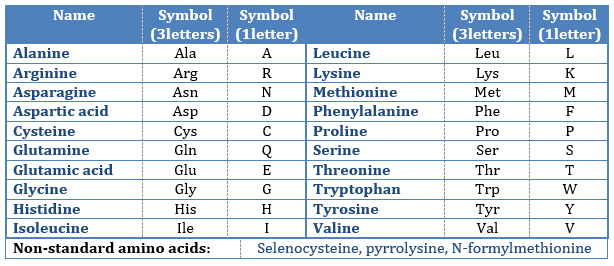
Les AA sont généralement écrits par une abréviation de 3 lettres triées en fonction de leur groupe fonctionnel R
- hydrophobe non polaire: pas d’interaction avec l’eau :
– la proline: son R est cyclique et se lie au groupe amine de l’AA. Il interdit la rotation de l’AA.
-la méthionine: elle possède un atome de soufre
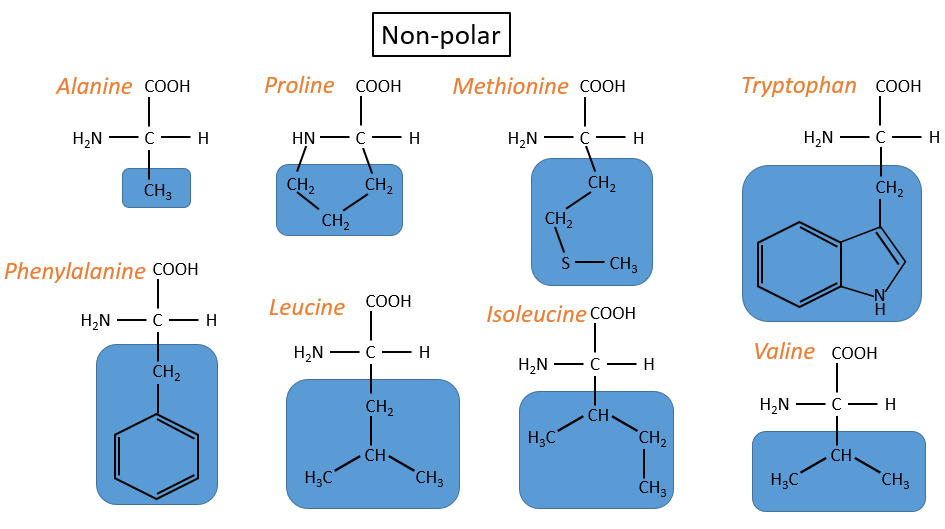
2. neutre polaire: peut réagir avec le solvant. Ils sont polaires parce que R est très petit
-cystéine: ils se lient ensemble via des liaisons S
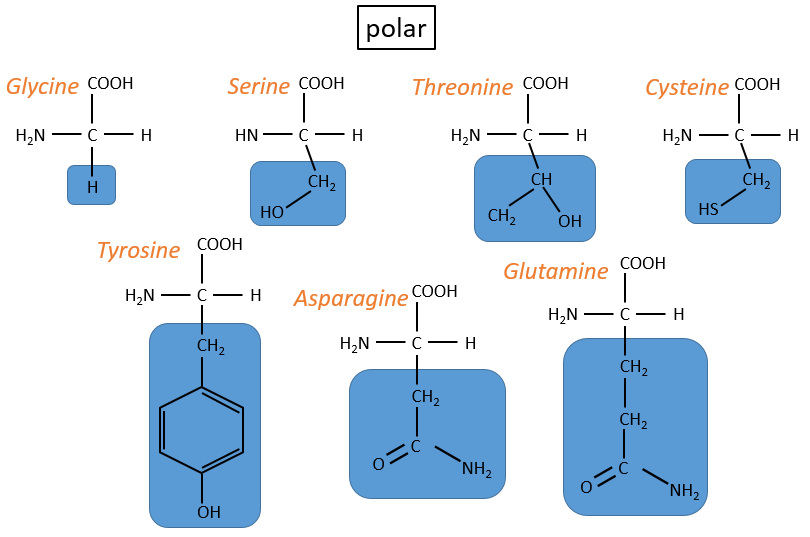
3.chargé polaire
– acides: with COOH
– basiques: with amine derivatives
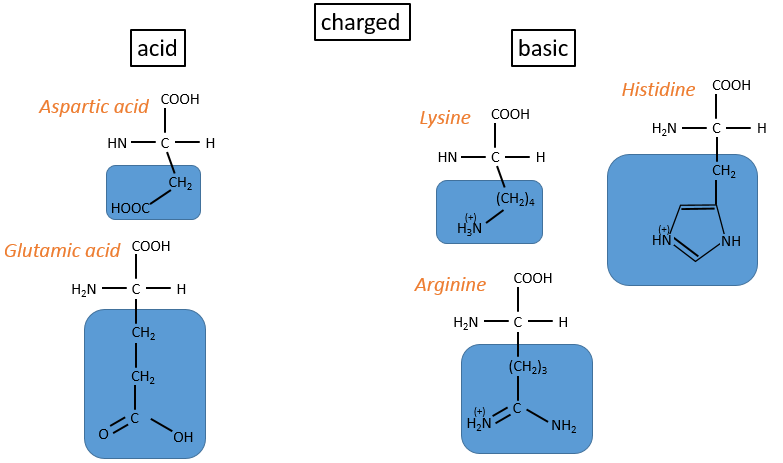
L’isoleucine et la thréonine ont un carbone asymétrique. Seul le L est naturel.
Comme zwitterions, les acides aminés ont un point isoélectrique qui dépend de la nature de R. On peut facilement déterminer la composition d’une protéine grâce à cette propriété: une fois hydrolysés, les acides aminés qui composent la protéine peuvent être séparés par chromatographie ou électrophorèse et déterminer leurs proportions. Il existe également un moyen de déterminer le dernier acide aminé de la protéine (terminé par NH2): avant l’hydrolyse, on utilise le réactif de Sanger (1-fluoro-2-4-dinitrobenzène). Ce groupe coloré est fixé sur l’amine et la liaison ne peut pas être hydrolysée. Nous pouvons donc l’identifier après la chromatographie. Une autre méthode est la dégradation d’Edman. Dans ce cas, un isothiocyanate de phényle réagit avec le résidu amino-terminal pour former un thioamide. La liaison peptidique suivante est affaiblie et peut être clivée sans hydrolyse en raison de la formation d’un cycle.
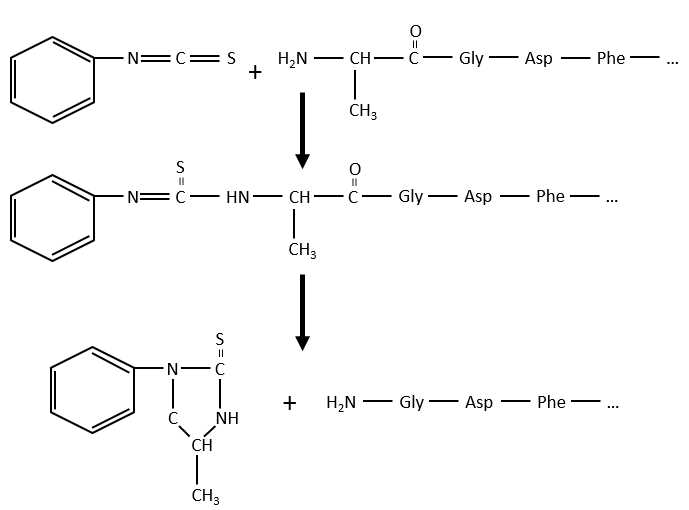
Le processus peut être répété plusieurs fois pour déterminer la séquence amino-terminale initiale.
Les interactions entre l’AA de la protéine avec l’autre AA et avec le solvant sont responsables de la structure de la protéine.
Chapitre 4: Structure primaire des protéines
La structure primaire d’une protéine est la succession, ou la séquence, de l’AA. Les protéines sont constituées d’une chaîne linéaire d’acides aminés. Cette chaîne linéaire prend une structure 3D (structures secondaires et tertiaires) en raison des interactions entre les séquences de la chaîne et les interactions (hydrophobes ou hydrophiles) avec l’environnement. L’ordre des AA et leurs quantités sont bien définis pour chaque protéine. La première structure jamais déterminée était celle de l’insuline. Cette protéine a une longueur de 51 AA, ce qui est petit en comparaison avec d’autres protéines pouvant atteindre 8000 AA de long.
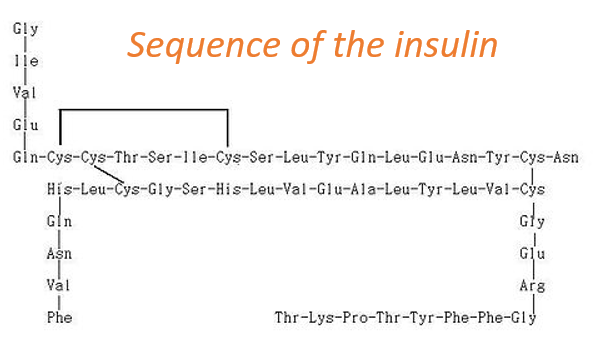
A l’exception des ponts disulfures entre les cystéines, cette protéine peut être vue comme deux chaînes linéaires avec respectivement 21 et 30 AA. Comme l’insuline n’est pas composée d’une seule chaîne, cette protéine n’est évidemment pas le produit primaire d’un ribosome. Quelques opérations supplémentaires ont été appliquées aux formes précurseurs de l’insuline pour obtenir la protéine fonctionnelle. Nous verrons ce processus plus en détail plus tard.
Pour déterminer la structure primaire d’une protéine, nous avons besoin qu’elle soit pure. Pour séparer les protéines des autres molécules, nous effectuons une dialyse: la solution contenant les protéines dans un sac avec une membrane poreuse à travers laquelle les petits ions peuvent passer mais pas les macromolécules. Une fois l’équilibre atteint, on répète le processus pour obtenir la meilleure pureté possible. Nous devons encore séparer les macromolécules et cela se fait:
par chromatographie :
– ionique: les protéines ont une charge qui dépend du R des acides aminés. La charge dépend du solvant utilisé. À un pH donné, la protéine cible est chargée positivement. Le placement d’un polymère chargé négativement dans la colonne retient la protéine pendant que les autres passent à travers la colonne. Après un certain temps, nous changeons de solvant pour délier la protéine du polymère.
– d’exclusion: les protéines sont séparées en fonction de leur taille. Les grandes protéines se déplacent plus vite que les petites car elles ne peuvent pas pénétrer dans les trous des billes composant la phase immobile.
– ligands: la protéine peut se lier avec des ligands spécifiques. Normalement, seule cette protéine devrait se lier, ce qui assure une grande pureté.
par électrophorèse:
les protéines sont séparées sur la base de leur point isoélectrique: les protéines sont placées sur un gel de polyacrylamine dont le pH n’est pas uniforme mais a un gradient. Comme les protéines sont chargées en fonction du pH du solvant, il se déplace jusqu’à ce que sa charge devienne neutre. Après cela, nous prenons le gel et l’appliquons sur un second gel long et poreux où les protéines sont déplacées par l’application d’une charge et leur vitesse dépend également de la taille de la protéine. De cette façon, nous obtenons une séparation 2D des espèces.
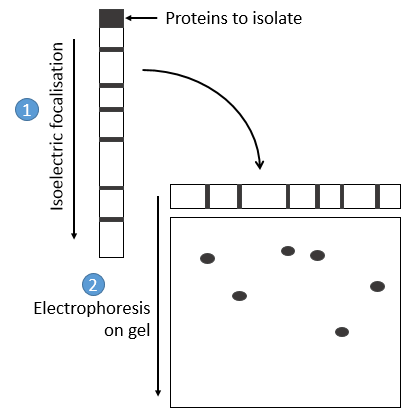
Une fois les protéines isolées, nous pouvons commencer à déterminer sa structure. Pour ce faire, nous utilisons un exopeptidase: son rôle est de ne cliver que la liaison avant le dernier AA. Le problème est que les enzymes ne sont pas synchroniques: elles ne commencent pas toutes simultanément et certaines chaînes peuvent être clivées plusieurs fois tandis que d’autres sont clivées une fois ou pas du tout. Il peut donc y avoir un mélange d’acides aminés dans la solution et la détermination de la bonne séquence peut être difficile. Pour minimiser ce problème, l’expérience doit être très courte.
Une autre méthode (d’Edman) consiste à affaiblir la dernière liaison peptidique et ensuite à utiliser un réactif faible qui n’hydrolyse que cette liaison. Dans le cas présenté, un isothiocyanate de phényle réagit avec le résidu amino-terminal pour former un thioamide. La liaison peptidique suivante est affaiblie et peut être clivée sans hydrolyse en raison de la formation d’un cycle.
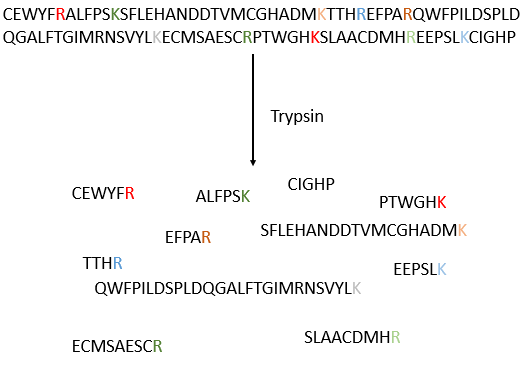
Le procédé peut être répété plusieurs fois pour déterminer la séquence amino-terminale initiale mais le rendement de la réaction n’est pas de 100%. En conséquence, il ne peut être répété que 30 fois. De plus, parfois les chaînes se rompent et nous avons donc une nouvelle extrémité qui donne des résultats différents. De toute façon 30 AA n’est pas assez bon pour déterminer la structure des protéines qui peuvent être longues de 8000 AA. L’ordre des 30 premiers acides aminés ne donne aucune indication sur la nature des acides aminés suivants. La seule façon de déterminer la structure est de commencer par fragmenter la protéine en petits morceaux. Nous allons essayer de couper la protéine seulement entre certains acides aminés pour avoir des points de référence. Il existe certaines enzymes endopeptidases spécifiques qui clivent les protéines seulement après un acide aminé particulier. Il détecte la présence d’un R spécifique, s’y lie et clive la liaison peptidique. La trypsine est une enzyme qui clive la liaison peptidique après une lysine ou de l’arginine.
Nous séparons les fragments par chromatographie et déterminons la séquence de chaque fragment (avec la méthode d’Edman par exemple). Pourtant, nous ne savons pas dans quel ordre les fragments sont dans la protéine. Le processus est répété avec une autre endopeptidase spécifique. Après plusieurs fragmentations et séquencements, nous pouvons essayer de comprendre quelles sont les séquences communes aux différentes fragmentations et reconstruire toute la séquence.
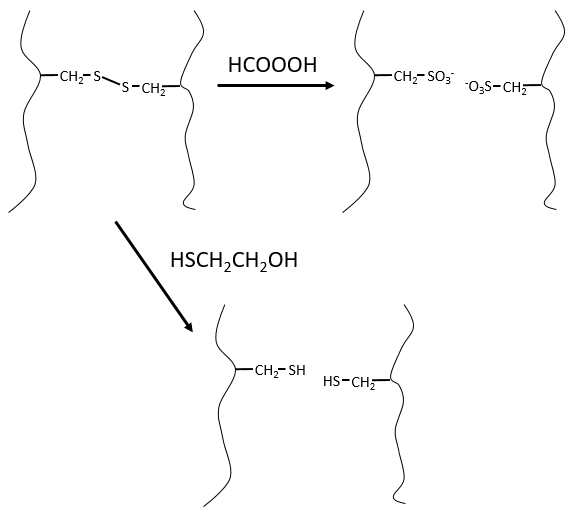
Ce serait parfait s’il n’y avait pas de liaisons SS le long de la chaîne peptidique. Il y a donc une étape qui doit être faite avant la fragmentation: nous utilisons l’acide performique (HCOOOH) pour oxyder les sulfures. Cette méthode est irréversible. Une seconde méthode, réversible, peut être utilisée à la place: le mercaptoéthanol réduit les sulfures.
Nous pouvons reprendre la structure primaire en 4 points:
la chaîne est linéaire et non ramifiée.
entre les acides aminés, les seules liaisons covalentes sont les liaisons peptidiques et les liaisons SS entre les cystéines. Les autres interactions sont l’attraction / la répulsion entre les groupes chargés et les liaisons H.
la séquence est complètement définie et arbitraire: une partie de la séquence ne définit pas le reste de la séquence. Par exemple, si on connaît 10 acides aminés, on ne peut pas dire que les 5 suivants sont une guanine, une cystéine, etc …
les protéines de différentes espèces sont similaires mais pas identiques. Il y a quelques fragments clés qui sont communs mais la structure entière peut varier. Une exception est l’histone. Cette protéine est commune à toutes les espèces eucaryotes: c’est la protéine responsable de la compaction de l’ADN dans le noyau cellulaire. Même si l’information contenue dans l’ADN diffère d’une espèce à l’autre, sa structure est identique et la protéine responsable de son enroulement/déroulement est donc la même pour toutes les espèces eucaryotes.
Certaines protéines fixent un (ou plusieurs) monosaccharide. Ce processus est appelé glycosylation et conduire à une glycoprotéine.
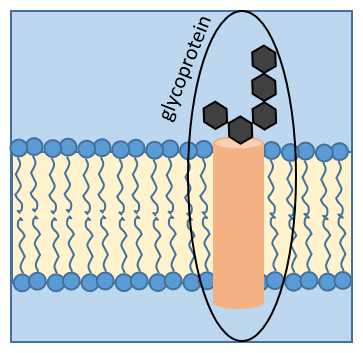
Le monosaccharide peut être fixé sur un atome d’azote (glycosylation N-liée, exclusivement sur l’asparagine) ou sur un atome d’oxygène (glycosylation O-liée). Le monosaccharide peut lui-même être lié à une chaîne de monosaccharides. Nous observons fréquemment des glycoprotéines dans les membranes où elles jouent le rôle de récepteurs. La présence du monosaccharide sur la protéine permet une grande diversité dans les récepteurs pour les cellules.
Chapitre 5: Structure 3D des protéines
La structure de la protéine est obtenue lors de la formation de la protéine. La structure de la protéine est nécessaire à sa fonction: certains sites actifs sont présents sur les protéines. Ces sites sont hautement spécifiques à un substrat cible. Les autres substrats ne peuvent pas atteindre le site actif.
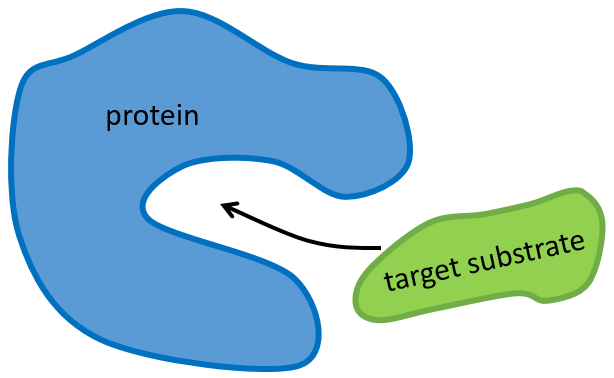
Le reste de la molécule est principalement là pour assurer la spécificité de la réaction ou une modification de la conformation de la protéine une fois qu’un site actif est activé (pour soumettre un signal par exemple). La chaîne peptidique peut également aider la réaction à se produire par l’application d’une pression sur une liaison spécifique de la molécule cible.
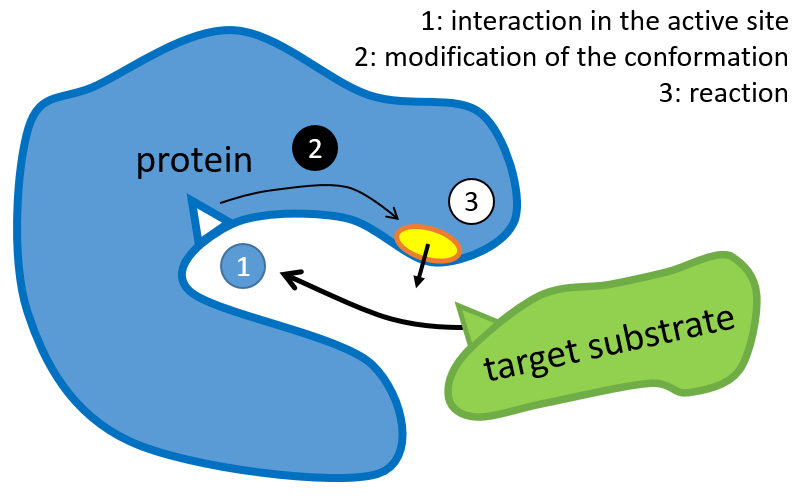
Une protéine est dénaturée lorsque sa conformation est modifiée. Par conséquent, sa fonction est perdue. Cela peut se faire par chauffage (~ 60 ° C) ou par une base / acide fort, … Il est fréquent que dans ces conditions la protéine précipite.
La détermination de la configuration spatiale de la ribonucléase a été faite en 1950.
Cette protéine possède 4 liaisons disulfuriques (8 cystéines). Anfinsine a placé la protéine dans une solution avec du mercaptoéthanol et de l’urée (NH2-CO-NH2). Le mercaptoéthanol clive les liaisons S-S tandis que l’urée forme des liaisons H avec la protéine. L’activité de la protéine a diminué de 99%. La conformation normale de la protéine pourrait être obtenue en plaçant la solution dans un sac de dialyse: en plaçant le sac dans une solution claire sans urée et sans mercaptoéthanol, ces molécules sortent du sac pendant que la protéine reste à l’intérieur. Son activité revient à 100%. Il est intéressant de noter que les liens S étaient tous formés au bon endroit (parmi 105 possibilités).
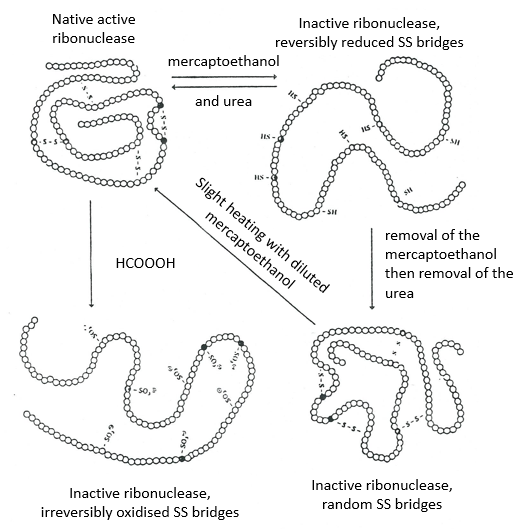
Si nous enlevons seulement le mercaptoéthanol (la solution à l’extérieur du sac de dialyse contient déjà de l’urée), les liaisons S sont faites mais au mauvais endroit.
Toutes les protéines ne retrouvent pas leur forme fonctionnelle après une dénaturation. Ils sont construits séquentiellement au cours de leur synthèse et les interactions entre les chaînes sont réalisées avant la synthèse complète de la protéine. Il est donc inhabituel que la séquence qui a été faite se lie d’abord avec l’une des dernières séquences. Cependant, après une dénaturation, n’importe quelle partie de la chaîne peptidique peut se lier à n’importe quelle séquence de la chaîne, quel que soit l’ordre de formation.
Certaines protéines sont là pour aider au bon déploiement des autres protéines. Ils sont appelés protéines du stock de chaleur (hsp70 et hsp60): après une augmentation de la température, plusieurs hsp70 reconnaissent les parties hydrophobes des chaînes peptidiques et se lient à la protéine. Il aide la protéine à atteindre la conformation correcte et la hsp70 laisse la protéine suivante. La hsp60 agit sur des protéines déjà déployées à tort et corrige leur structure.
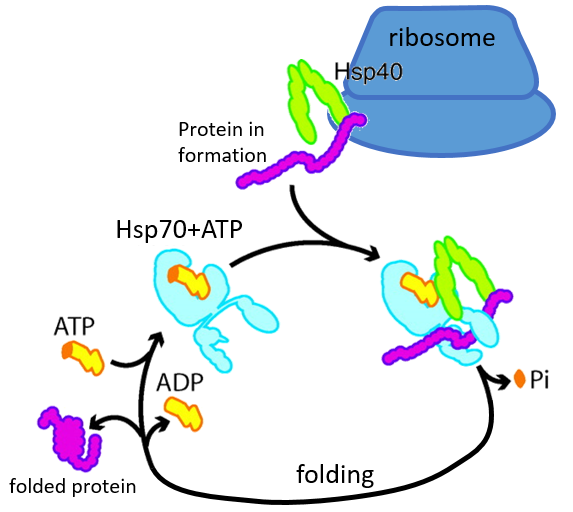
Détermination de la structure des protéines
La méthode est basée sur la diffraction des rayons X. Des cristaux des protéines nous obtenons une distribution des atomes. Payling et Corey ont analysé les distances interatomiques entre les différents atomes dans les acides aminés. Ils ont découvert que la liaison peptidique a une longueur comprise entre la longueur d’une liaison C-N et une liaison C = N.
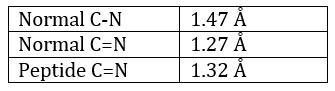
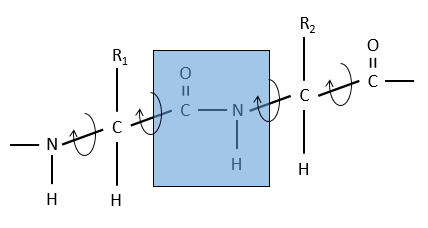
La raison est la résonance avec le carbonyle. La liaison peptidique est donc rigide, presque toujours trans, mais les liaisons autour de la liaison peptidique peuvent tourner.
Secondary structure
The secondary structures of a peptide chain are small “motifs” due to the interaction between nearby AA. The first structure, the α helix, was proposed in 1951. The distance between spires of the helix is 0.54nm and the length of one AA is 0.15nm. There are thus approximatively 3.6 AA by spire. All the R groups are at the outside of the helix, which is always L. There are H bonds between AA distant of 3-4 AA
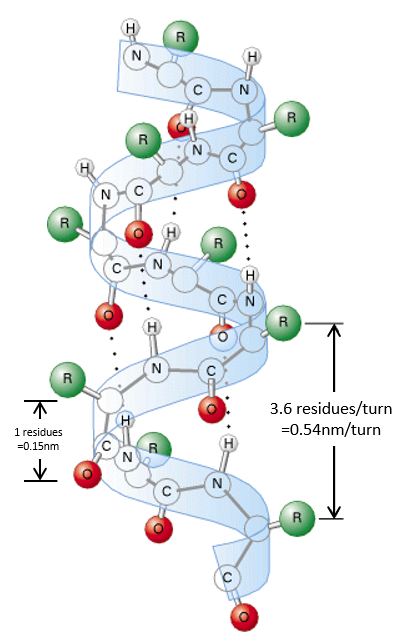
All the AA cannot take place in helices. The structure is compact and AA with voluminous R group (for instance with an aromatic in R) would deform the helix.
The proline cannot be part of a helix too: its R is covalently bound to the nitrogen of the peptide bond. The liaison is thus particularly rigid and cannot be placed in one helix.
A third exclusion of the helices is charged amino acids. Imagine a helix with several –COOH groups. The structure is stable in neutral conditions but if the pH changes, there can be a lot of nearby COO-, what is unstable.
We find a lot of α helices in fibrous proteins such as the keratin α (found in the hairs). The hydrophobic AA form helices and we find them in lipid membranes.
The β sheet structure is a stretched out structure of the peptide chain. The chains place themselves in parallel or in antiparallel to form a compact and rigid structure.
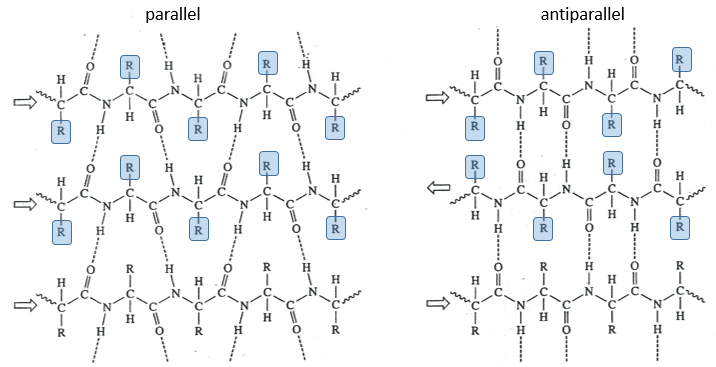
The chains are bond by H bonds and the distance between the chains is 0.35nm. The R groups of the AA have to be small to fit in the space between the chains. Even smaller in the antiparallel β sheets because the R groups are head to head with the R groups of the other chains. In the parallel β sheets, the R groups face one hydrogen. This kind of structure is also largely found in fibrous proteins such as the fibroin (in the silk) or the β-keratin (in feather).
There are also β helices, formed of β sheets arranged in one helix, but these are less frequent.
Tertiary structure
The tertiary structure is the result of long distance interactions. In a general way we represent helices by tubes/helices and β structures by arrows. The extremities of the chain are indicated by NH3+ and COO–.
Kendraw determined the tertiary structure of the myoglobin of cachalots. To do so he marked with heavy atoms some known sequences of the molecules.
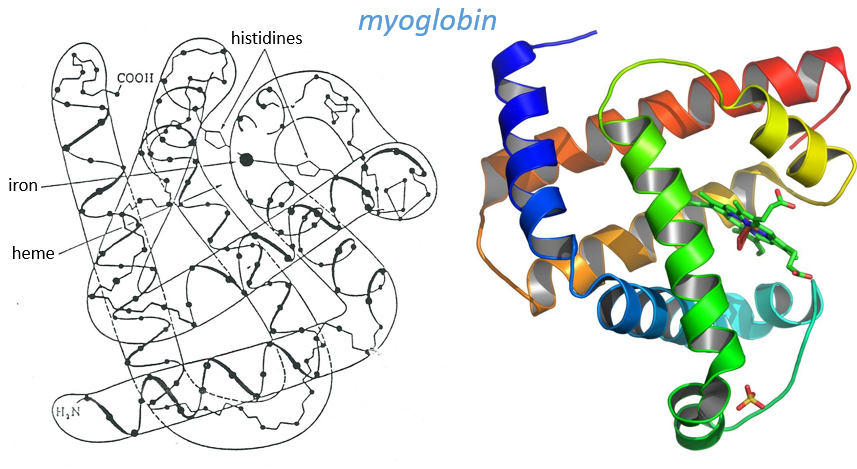
The structure is compact and possesses 8 helices of variable sizes. The groups inside the protein are nonpolar at the exception of two histidines. The AA in the helices may vary for different species but the angles remain the same.
The heme group is the one that fixes the oxygen to supply the muscles. The heme is a tetrapyrol on which one Fe2+ is fixed at the centre.
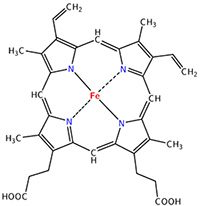
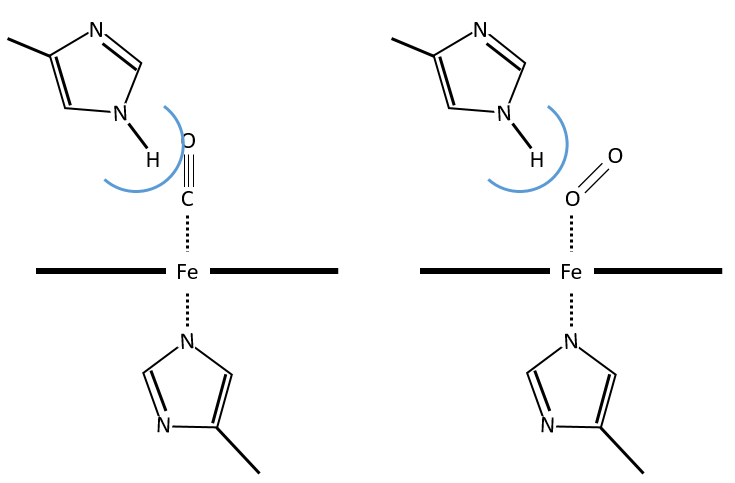
The iron has 6 liaisons and the two last are perpendicular to the plane made by the 4 other liaisons and bind with the two histidine’s. The heme is in the hydrophobic part of the protein because otherwise the iron would be oxidised by the blood. O2 fixes on the iron instead of one histidine. Yet, the presence of the histidine is very important: oxygen can easily bind on the heme but CO has an affinity for the heme 2500 larger than the one of the O2 without the presence of histidine’s. So if there are a few molecules of CO in the air, they would bind to the myoglobin and stay on it for a long time, forbidding oxygen to reach the muscles. The way to heal such an asphyxia is to place the person in a hyperbaric box full of oxygen (and obviously without CO) where we play on the equilibrium to replace the CO by O2. If there are 5000 molecules of O2 for each CO in the air, then the O2 is more susceptible to bind with the haem. Fortunately, histidine’s are close to the iron and prevents sterically the CO to bind correctly with it. The oxygen is not obstructed by the histidine because the angle of liaison is not the same (see the figure below). Considering the histidine, the affinity for the CO drops down to 200 time the one of the oxygen.
Types of liaisons in the tertiary structure:
- hydrophobic interactions
- electrostatic liaisons
- S bonds (cysteines)
- H bonds
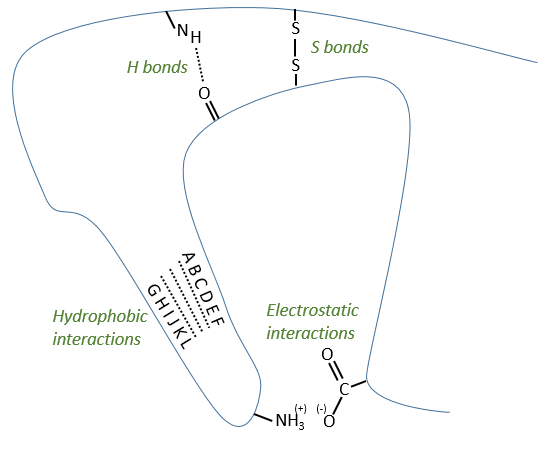
Denaturation of the tertiary structure
- by heating: the heat is enough to break weak liaisons such as the hydrophobic interactions. As they break, the structure shambles and the hydrophobic parts enter in contact with the aqueous environment. As a result, the protein precipitates
- by urea: the urea breaks the H bonds
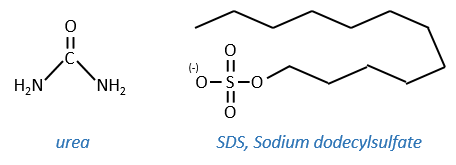
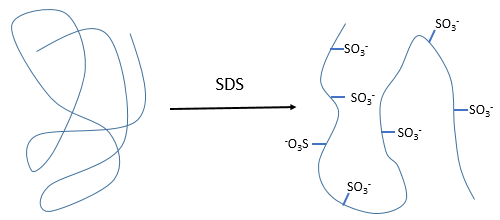
- by detergent: it denatures and solubilises the protein. For instance the SDS (sodium dodecylsulfate).
The hydrophobic chain of the detergent interacts with hydrophobic sequences of proteins. At this point the SO3– is transferred on the protein, generating some hydrophilic zones that modify the structure of the protein.
Quaternary structure
Some proteins aggregate together to form a bigger structure. The parts of this structure are called protomers and are only active if they are together. For instance, the haemoglobin is composed of four protomers, two α and two β.
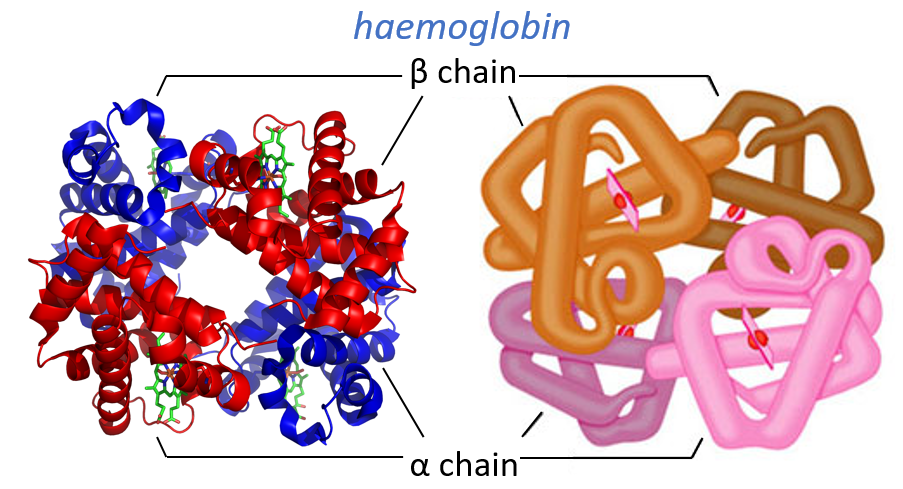
The function of the haemoglobin is to transport the oxygen in the blood and to transfer it to the myoglobin at the muscles. By the way, the protomers are alike with the myoglobin but only in the tertiary structure. The primary structures are very different except at the corners. To give an idea of the role of the haemoglobin, without them there would be 5ml of O2 by litre of blood. With them in the blood, there are 250ml of O2 by litre of blood. Another difference between the myoglobin and the haemoglobin is their curve of fixation of the oxygen. i.e. the percentage of saturation of the protein as a function of the partial pressure in O2.
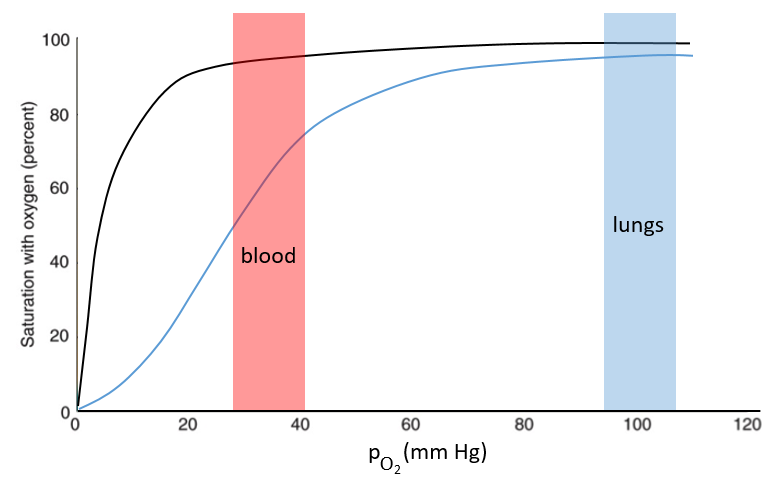
The curves have similar shapes but the one of the haemoglobin is shifted in larger pressures of O2 In other words, and as expected, the two proteins don’t fix the oxygen at the same place. The partial pressure is high in the lungs and is around 40mm Hg in the muscles and tissues. The two proteins are saturated in oxygen at high pressures but the myoglobin has a rate of saturation that increases much earlier than the one of the haemoglobin. As the myoglobin is only found in the muscles, the haemoglobin fixes oxygen in the lungs and transports it to the muscles. In the muscles, the myoglobin has approximatively 40% more affinity for the oxygen than the haemoglobin. Haemoglobin drops some of the oxygen that is collected to the myoglobin.
The difference of behaviour is explained by the structure of the haemoglobin. The fixation of the first oxygen is difficult and induces a modification of the conformation of the protein through the rotation of two protomers. It opens up the way to a larger central cavity of the protein and the oxygen can now enter more easily. The form without oxygen is called deoxyhaemoglobin and the form with oxygen is called oxyhaemoglobin.
In the cavity, there are some charged amino acids that may enter in interaction with diphosphoglycerate (DPG), a molecule present near muscles and tissues but not in the lungs. With the DPG on the haemoglobin, the curve of fixation of oxygen goes down. By selectively binding to deoxyhaemoglobin, BPG makes it harder for oxygen to bind haemoglobin and more likely to be released to adjacent tissues. The concentration of DPG depends upon the location in the body but we find it essentially in the muscles and in the blood, what explains the difference of the curves of the myoglobin and of the haemoglobin. When we go in altitude, the pressure decreases significantly and we also produce more DPG. It allows the muscles to work better because there is a better transfer of oxygen from the haemoglobin. The DPG is not immediately degraded when we come back to a normal altitude and the muscles continue to be more efficient for a period of time. It is why athletes are often going to the mountain to practice before important events.
The Bohr effect
Haemoglobin can also fix CO2 and protons (both are products of the muscles). Their fixation favours the exchange of oxygen at low pressures. Basically, when we do sport, or run away from a danger, muscles work, produce CO2 and protons. The body uses those products as a signal to ask for more oxygen to maintain the effort. It is an allosteric effect: the activity of the protein is modified by agents that act on a different place of the protein than the active site. The CO2 is fixed on the terminal NH2 of the peptide chains while the protons are fixed on histidines.
Enzymes
Enzymes catalyse chemical reactions with a huge specificity. Usually there is only one target substrate but sometimes other molecules can take place in the active site and block it. The names of the enzymes are often related to the target substrate. For instance, the enzymes responsible for the cleavage of RNA is the RNAase, of lipids a lipidase, of amino acids a protease.
The activity of enzymes is modulated by several factors
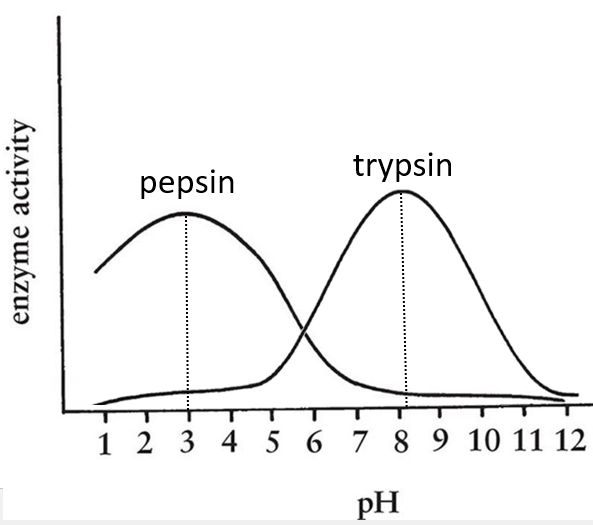
- pH: there is usually a maximum of activity at a given pH. For instance the pepsin and the trypsin are two enzymes that are respectively active in the stomach and in the intestine. It is thus normal that the optimum of pH of the pepsin is much lower (more acidic, pH»3) than the one of the trypsin (pH»8).
- cofactors: they can be ions or coenzymes and their presence will affect the activity of the enzyme. As for the pH, there can be a maximum of activity depending on the concentration of the cofactor.
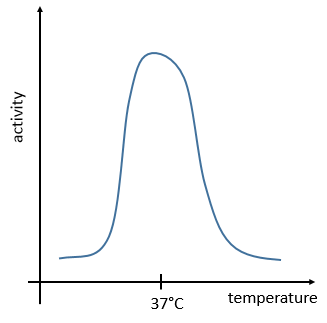
- temperature: chemical reactions obey to the law of Arrhenius
![]()
The temperature increases the speed of reaction but if it increases too much the enzyme is denatured. There is thus also an optimum of temperature. In the body, this optimum is usually around 37°C.
- saturation: the concentration of enzyme is often small in comparison to the concentration of substrate so it limits the maximum speed of reaction. If we increase the concentration of enzyme, the maximum speed increases but it is only true up to a given point. After this point, we can increase the concentration of enzyme but the speed will not change. It is translated by the constant of Michaelis-Menten (see the chapter on kinetics).
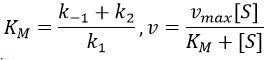
A small KM means that the enzyme reaches its full speed for lower concentrations. Half of the maximum speed is reached when the concentration of substrate equals KM.
Chapitre 6: acides nucléiques
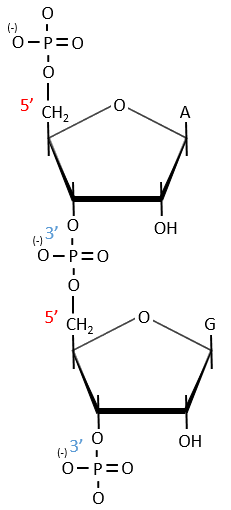
Nucleic acids are composed of monosaccharides connected by phosphoester liaisons and wearing a base. One monosaccharide and its base are called one nucleoside. One monosaccharide, its base and one phosphate are called a nucleotide. RNA and DNA are composed of one similar monosaccharide, the ribofuranose, with the difference that the 2’ has an H on the DNA in place of an OH for the RNA. It is the reason of their names: the ribonucleic acid (RNA) and the deoxyribonucleic acid (DNA).
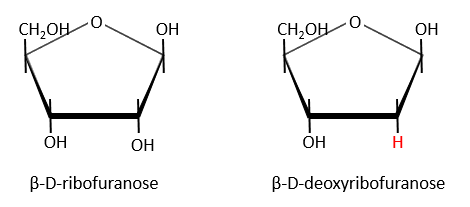
Monosaccharides are bound together in 3’-5’ and the base is bound by the OH on 1’. There is a total of 5 bases.
- purine bases: they are composed of two aromatic cycles with nitrogen atoms in the cycles. They absorb the UV at 260nm.
- adenine (A)
- guanine (G)
- pyrimidine bases: they are composed of one aromatic cycle and also absorb UV.
- uracil (U, only found in RNA)
- thymine (T, only found in DNA)
- cytosine (C)
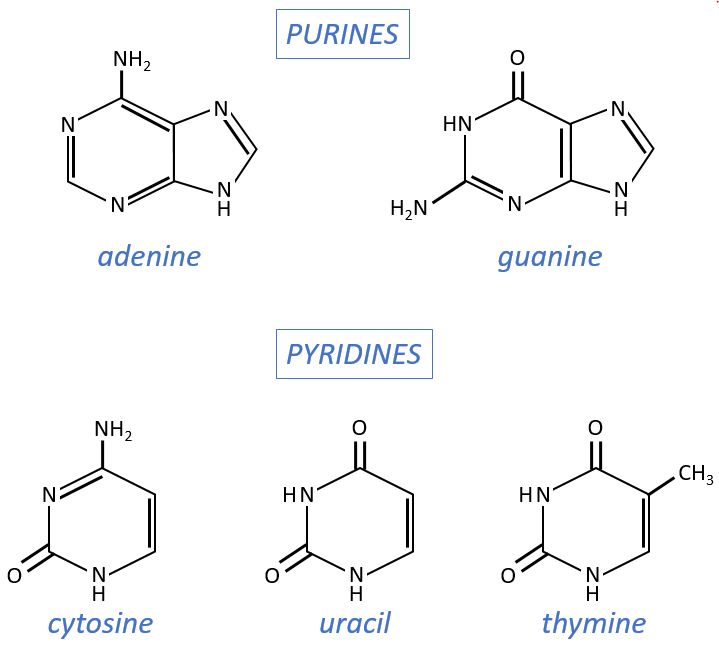
Nucleosides are the combination of one base with one monosaccharide. The names of nucleoside are directly related to their base.
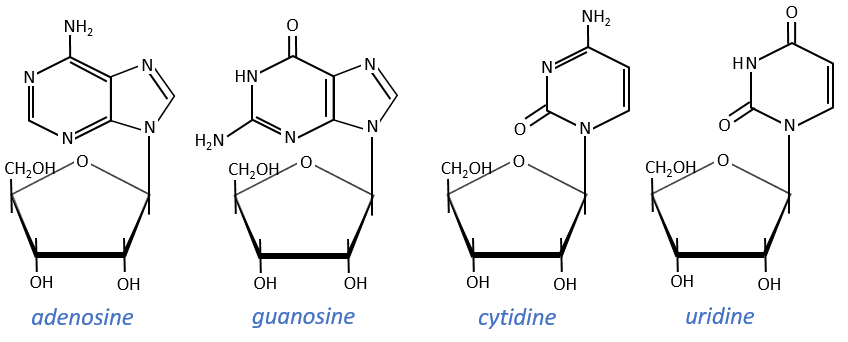
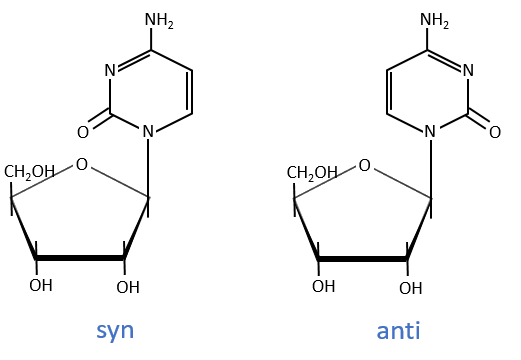
The same is true for the deoxynucleosides. The prefix deoxy is just added to the name of the corresponding nucleoside. There is a stereochemistry in the orientation of the base and the monosaccharide. The liaison can either be in anti or in syn.
Nucleotides are the combination of one nucleoside with one or more phosphates (in chains). The phosphates can be placed on 5’ or on 3’ by an ester liaison and phosphates are bound as acid anhydride of acid. The liaison between two nucleosides is a phosphodiester liaison.
One example: two important nucleotides are the adenosine diphosphate (ADP) and the adenosine triphosphate (ATP).
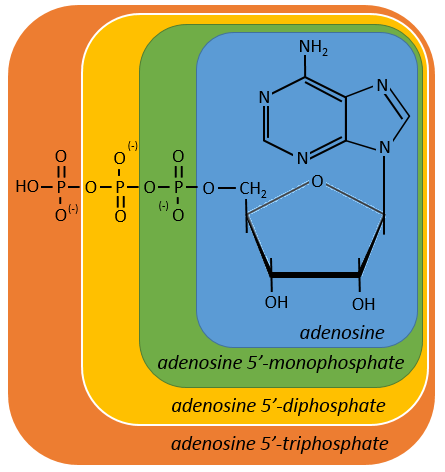
If the base was a deoxy~, we write a ∂ (or d) before the name (ex: ∂ATP)
Nucleotides absorb in the UV the same way nucleosides do.
A chain of nucleic acids has a polarity. It goes from the 5’ towards the 3’. A chain is written in this order in abbreviated:
![]()
The chains are also build following this order.
Cleavage of the chain
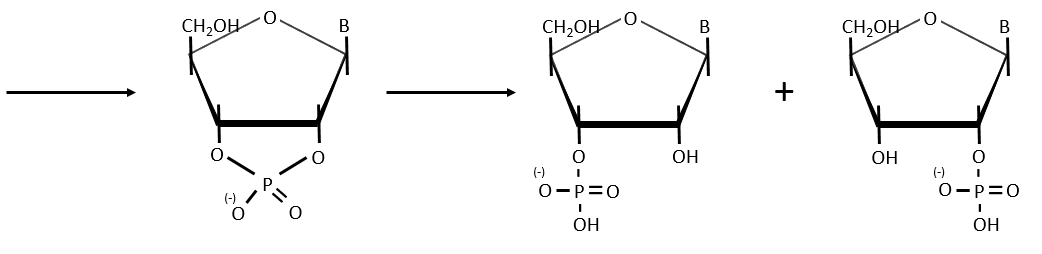
- By total acid hydrolysis, using a 12M HCl solution. It cleaves all the liaisons between the monosaccharides, the bases and the phosphates.
![]()
It is the harsh method, the following methods are gentler.
- By depurination: we work at pH=1.6 and at 37°C. The cleavage only works for the DNA and only break β-N-glycosidic bonds. β-N-glycosidic bonds are hydrolytically cleaved releasing a nucleic base, adenine or guanine, respectively.
- hydrolysis for RNA: we use NAOH 0.1M at 25°C (during 15hours). It only cleaves the RNA chains because the reaction involves an intermediate species that needs the OH in 3’
- enzymatic cleavages: some enzymes are specialised in the cleavage of nucleic chains. There are of two kinds: endonucleases and exonucleases. The firsts cleave liaisons inside the chain and the seconds cleave the chains starting at one extremity. It can go from 3’ to 5’ or from 5’ to 3’, depending on the enzyme. The extremity has to be free of phosphate to be cleaved. For instance, the phosphodiesterase that we have in the spleen only works if the 5’ extremity is ended by OH. It will free nucleosides 3’-phosphate. The phosphodiesterase that we find in the venom of snakes cleaves the 3’ extremity and forms nucleosides 5’-phosphate.
Endonucleases are usually not specific and give nucleosides 3’ phosphates. Yet there are some specific endonucleases that recognise a particular pattern in the chain. For instance, endonucleases of restriction are enzymes that we find in bacteria’s to protect themselves from bacteriophages. Bacteriophages are viruses that attack bacteria’s and try to inject their own DNA inside the DNA chain of the bacteria. The enzyme recognise a palindrome in the sequence of the DNA. It is called a site of restriction. This site is cleaved in a special way.
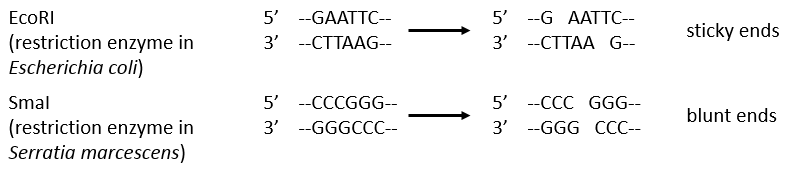
The resulting extremities may be sticky or blunt, depending if the cleavage is done at the same base or not on the two strands. The term sticky was chosen because they are easily joined back together by a ligase if there are several unpaired nucleotides.
The DNA of the bacteria is protected from this cleavage because its DNA was methylated by a methyltransferase after/during its formation.
Structure of the DNA
DNA has a helical structure that was determined by several experiments.
- Chayaff: he was studying the composition of the DNA in term of bases. He performed a total acid hydrolysis and analysed then the proportions of A, C, T and G. The result of its experiment was that the proportion of A is equal to the one of T and that the proportion of G was equal to the proportion of C. Moreover, the sum A+G=C+T.
- Wilkin and Franklin: They performed the XR diffraction of the DNA. They observed particular pattern with a two characteristic lengths of 0.34nm and of 3.4nm.
- Watson and Crick: From the experiment of Wilkin and Franklin, they gave a model of structure for the DNA: a double helix.
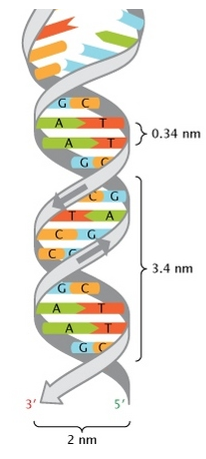
The chains of monosaccharides are at the outside of the double helix and the bases are facing each other at the inside of the helix. Each base can only be pairing one other base: A with T and C with G. It explains the equivalences in proportion.
The helix is stable thanks to the H bonds between the bases. There are 2 H bonds between A and T and 3 between C and T.
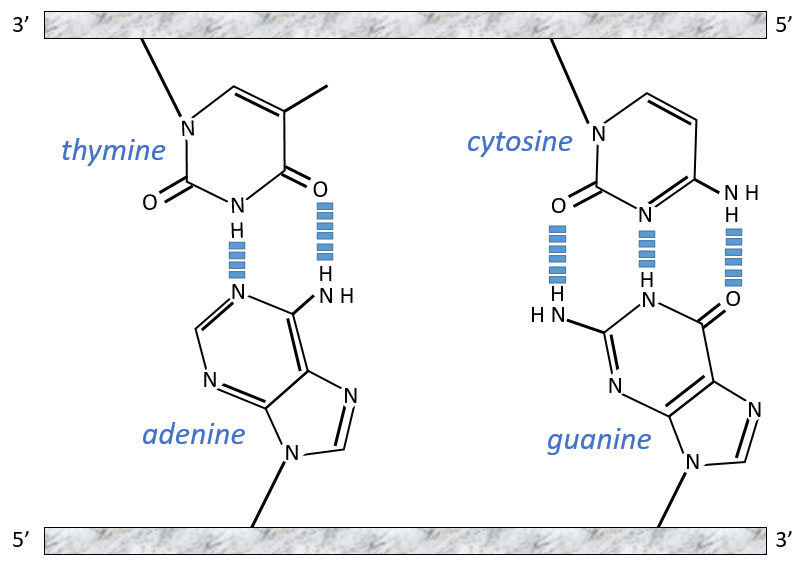
As they are surrounded by the hydrophobic chain of monosaccharides, the bases are protected from water that could interact with the H bonds linking the bases. There are also electrostatic interaction between the bases.
A heating (80-90°C) can separate the two “strands” of DNA from each other. When separated, they absorb more light than when they are coupled and we can observe a hyperchromic effect at 260nm.
The sites where enzymes cleave the DNA are always full of A or/and T. It is easier to open the helix here because there are less H bonds between the bases.
The length of the DNA varies between species and is not in helix for the prokaryotes for which the DNA is circular. The longest genome belongs to the “triton”
Replication of the DNA
During the mitosis, the cell splits in two cells, the DNA is reproduced and each new cell possesses the same genome than the cell they are made of, the mother cell. The DNA can spontaneously reform itself if it was denatured as it was shown by the experiment of Miseber and Slahl: they placed some bacteria’s in a solution the composition of which is controlled: the single source of nitrogen in the solution is NH4Cl and the nitrogen were marked isotopes. The bacteria’s form the bases of the DNA with this nitrogen. After a while, the DNA is centrifuged with a dense salt of CsCl. During the centrifugation, the salt goes to the bottom of the tube and the DNA stops at its density. As there are two isotopes of nitrogen (14N and 15N), there will be two layers of DNA with different densities.
We can thus isolate the light DNA from the heavy DNA. If we place them respectively in a solution of culture with 14N and with 15N, they can replicate. From the solutions, we extract some DNA, put them together and denature them (T=100°C). The strands of DNA are thus separated. When the solution is cooled down, the strands pair together but not necessarily with the strand they were paired with previously. After centrifugation, there are still the layers of DNA that were obtained previously but there is now a third layer between the two other, corresponding to the binding of one 14N strand with one 15N strand.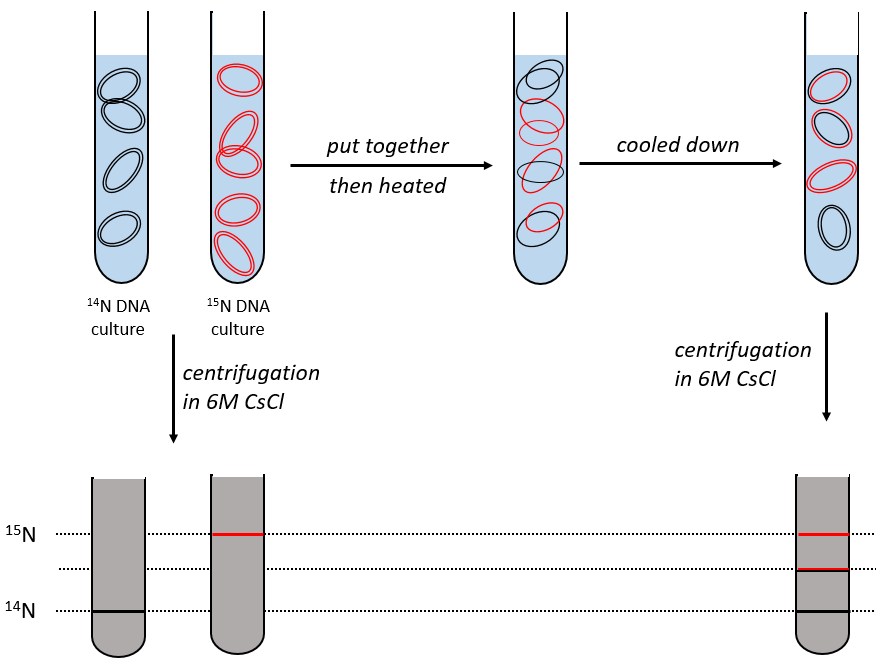
We can imagine three ways of replication for the DNA: we consider a mother strand of DNA and one daughter strand that is the replication of the mother strand.
- conservative replication: the two strands of the mother DNA remain paired after the replication.
- semi-conservative replication: one strand of the mother DNA pairs with one strand of daughter DNA.
- non-conservative replication: the sequences of mother and daughter DNA are mixed in both strands.
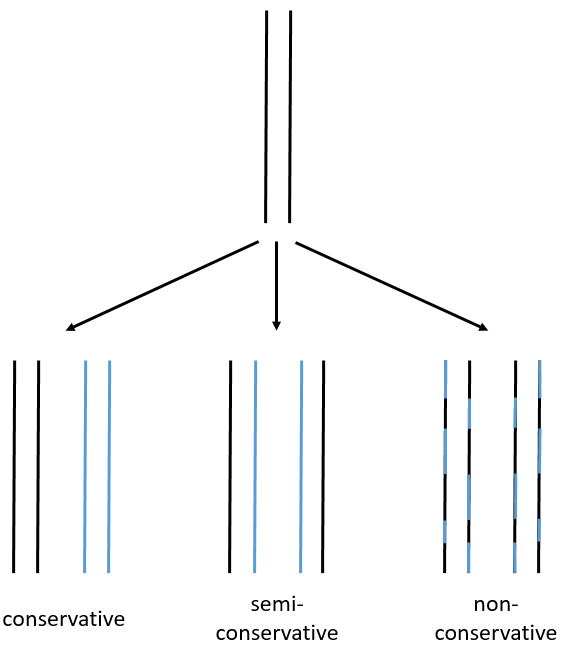
The replication of the DNA is semi-conservative. It can be confirmed by placing the 15DNA in a culture with 14N. If the replication was conservative, we would only obtain two layers of different densities. If the replication was non-conservative, there would be a continuous layer of DNA in the centrifugation tube. After one replication, there is only one layer (mix of 14N and of 15N). After two replication, there are two layers in the tube (14-15N and 14N). It confirms that the replication is semi-conservative.
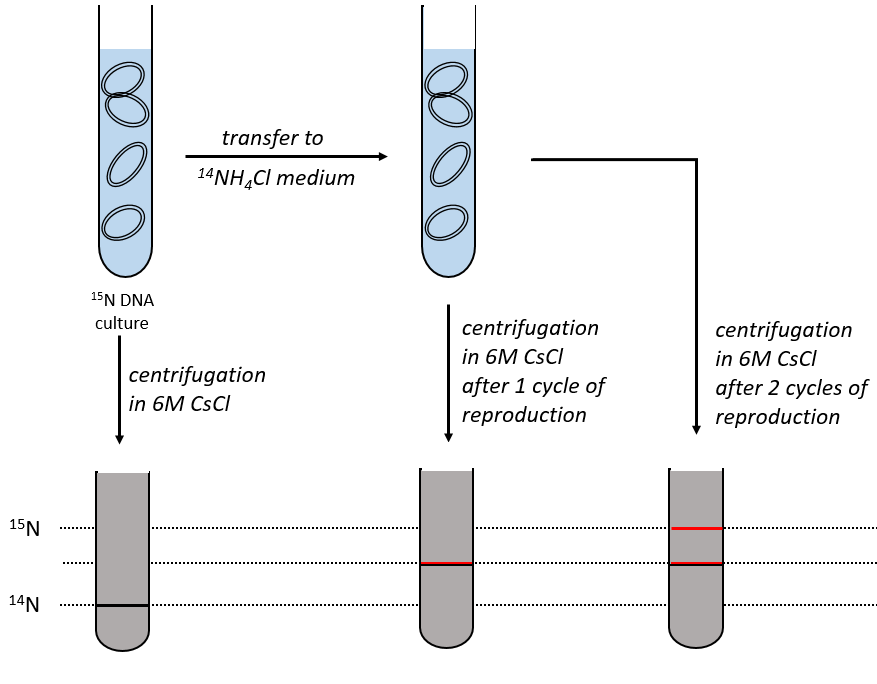
The replication of the DNA is done by the DNApolymerase, which takes one strand of DNA as model and replicates it from 5’ à 3’, adding one nucleotide by one. This addition is done from deoxynucleosides triphosphate and generate an inorganic phosphate (or pyrophosphate)
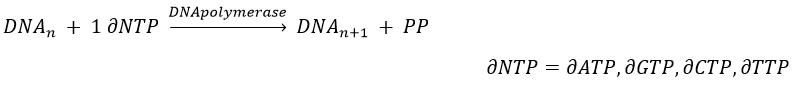
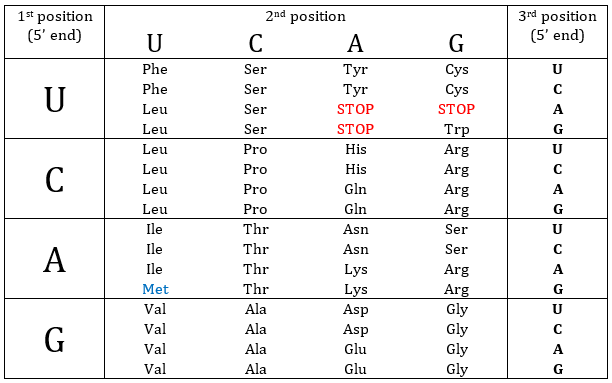
Nucleotides form triplets, called codons. The table below shows the codons and the names we call them with.
Determination of the sequence: the method of Sanger
To use this method, we need a complete strand of DNA and one fragment of it obtained via an endonuclease. The fragment is called a primer. We also need to prepare 4 different solutions. In each there are some DNA polymerases and some of each ∂NTP. One of the ∂NTP is marked. In the first solution, we add a few di∂ATP. In this dideoxynucleotide, the OH of the 3’ is missing and it stops the chain. In the second solution, we place a few di∂CTP, in the third a few di∂GTP and in the fourth a few di∂TTP. When we put the primer and the DNA in one solution, the DNApolymerase synthesises a strand at the extremity of the primer, copying the sequence of the DNA. However the synthesis will stop when one di∂NTP is added to the sequence. In each solution we know which nucleotide ends the sequence but the chains can differ in length: for instance in the first solution if one adenosine was to be added by the DNApolymerase, it can come from a ∂ATP or from a di∂ATP. In the first case the chain continues to grow and not in the second case.
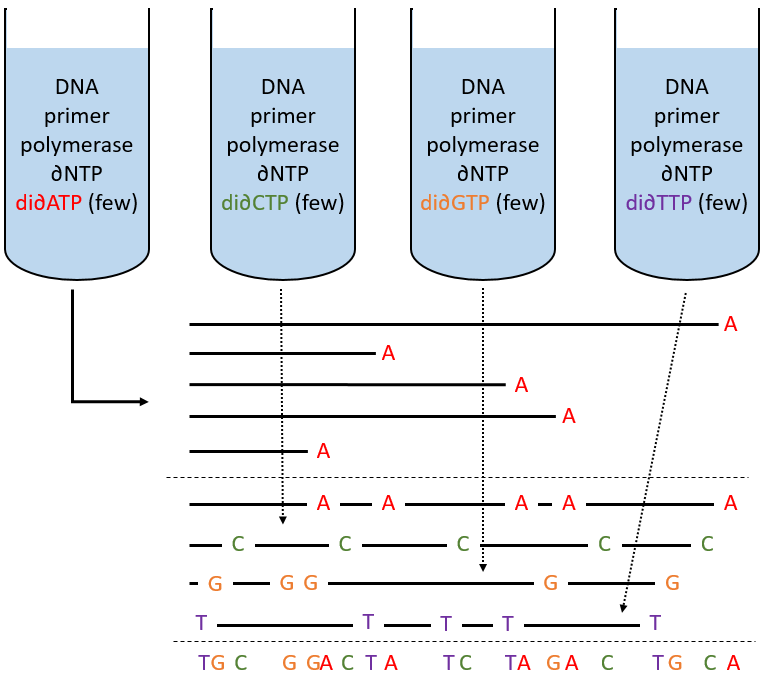
The same happens in the other solutions except that the strand ends by a different nucleotide. We analyse the 4 solutions in parallel on an electrophoresis gel. On this gel, the smallest molecules move faster than the long ones and they can be recognised via to the marked nucleotide. We can thus determine the size of each fragment knowing its final extremity. As a result, the complete sequence can eventually be determined.
Chapitre 7: Catabolisme du glucose
Its goal is to supply energy to the cell wherever it is needed. The glycolysis forms pyruvate from the glucose that can next be deteriorated anaerobically to form lactate or ethanol through fermentation. In 1870, Louis Pasteur discovered the functioning of yeasts. He isolated one yeast and added it to a wine that was not fermenting. The wine fermented. At this time, Pasteur believed in the vitalism so he did not search further. Later, the Buckner brothers were preparing extracts of yeast. As it was not easy to conserve, they put the extracts into sugar and it fermented. The yeast has thus not to be complete (or alive) to be effective. The extracts were composed of two molecules: one large enzyme that becomes ineffective when the temperature increases and one small molecule that was ineffective alone. In fact, the small molecule is a coenzyme of the big enzyme and the fermentation is only possible when both molecules are together. The complete process of the fermentation of the glucose was discovered in 1925 by Embdem and Meyerhof.
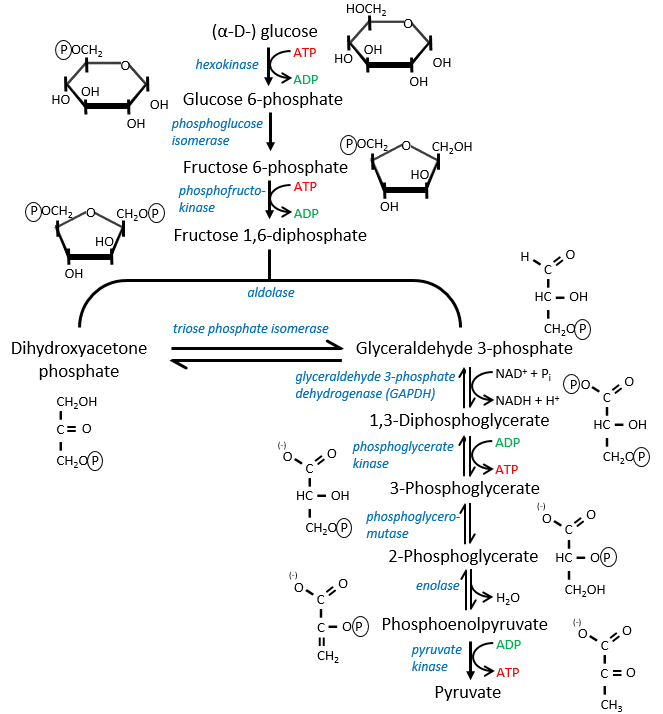
The first step is the phosphorylation of the glucose. The phosphate is added on 6’. For this reaction, as for the others of the glycolysis, an enzyme (the hexokinase/glucokinase) to form the ester and to cleave the anhydride of the ATP.
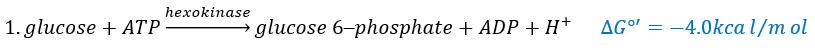
The second reaction involves the transformation of a pyranose into a furanose.
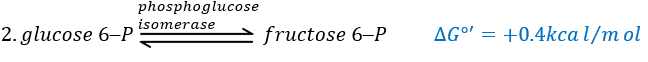
The third step is dependant of the needs of the cell in energy.
![]()
When the cell absolutely needs energy, its consume ADP and forms AMP. If the concentration of AMP in the cell increases then a signal is sent to the phosphofructokinase to increase the rate of the reaction. On the contrary, if the cell is full of ATP, then there is no need to make more of them and the reaction is slowed.
![]()
In the next step, the fructose is cleaved into two chains of 3 carbons, an aldose and a ketone that can be transformed into each other by the triose phosphate isomerase.
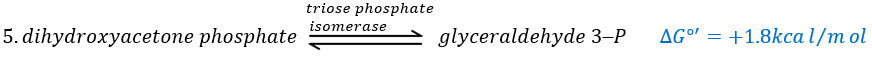
Because the reaction 5 is reversible, if the C1 of the glyceraldehyde was marked, we would find the fructose marked on 3’ or in 4’.
The next steps involve chains of 3 carbons. From one glucose, they are thus occurring twice.
![]()
The enzyme of the step 6 is the GAPDH (glyceraldehyde 3-phosphate dehydrogenase) and the NAD (nicotinamide adenine dinucleotide) is its cofactor and has to be in the active site of the enzyme for it to work. NAD+ is its oxidised form and NADH+H+ its reduced form.

The presence of the reduced form can be confirmed by a new peak of absorbance at 340nm. The reduction generates some energy to allow the formation of a phosphoanhydride, what is a liaison high in energy. It will thus generate a lot of energy when it is cleaved.
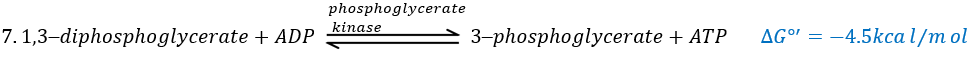
The seventh step uses the energy of this liaison to regenerate one ATP.
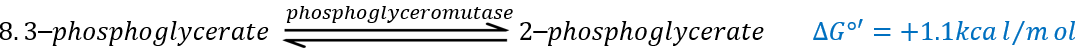
The eighth reaction displaces one phosphate. It is done by an enzyme called mutase.
![]()
The ninth step is an intramolecular reaction of oxidation. C2 is oxidised while C3 is reduced. We have now a phosphoenol the cleavage of which restores one ATP in the following reaction of tautomerization.
![]()
In total, two ATP were used during the glycolysis to form the trioses. These steps are thus using the reserve of energy of the cell. However two reactions form one ATP by triose. As there are two trioses by glucose and the isomerase can turn the ketone into the glyceraldehyde, so we form 4 ATP from the trioses. During the complete glycolysis, 2 ATP are thus formed that can be used by the cell. For anaerobic cells, it is the only way to produce ATP.
The NAD+ has to be regenerated by fermentation.
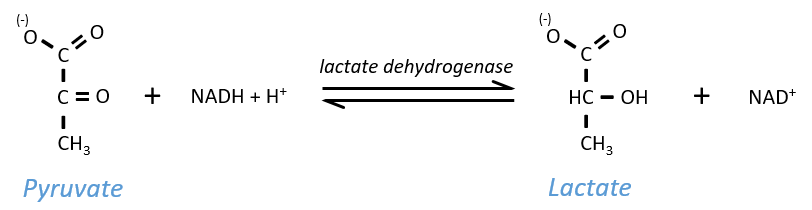
Lactic acid fermentation
The pyruvate, the final product of the glycolysis, is used to oxidise the NADH+H+ and form lactate that is next released in the middle.
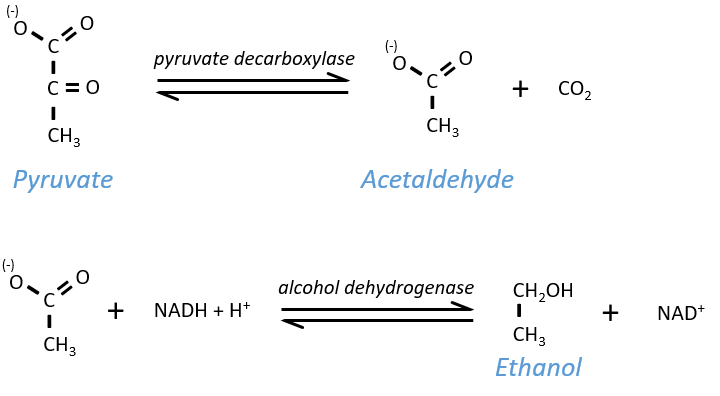
Ethanol fermentation
Also called alcoholic fermentation, this process also uses the pyruvate but is made in two steps. One first that involves the rejection of CO2 and the second that oxidises the NADH+H+ and frees some ethanol.
Comments on the glycolysis
- In the case of a lack of NAD+, or a too large quantity of glucose, more NAD+ can be formed from the “unused” triose, the dihydroxyacetone phosphate
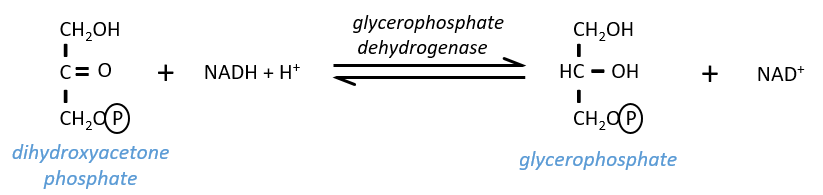
The reaction is in equilibrium and is only made in case of need. If the triose was essentially used to do this, the whole process of the glycolysis would be pointless: it would consume 2 ATP to form 2 ATP.
- Coupling of reactions
Some steps of the glycolysis have a positive ∆G0’. It is the case of the steps that form rich liaisons. In this way, the step 6 is coupled to the step 7 that cleaves the rich liaison to form an ATP.
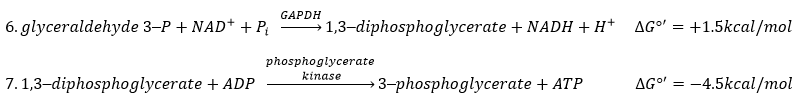
If we consider the two reactions at once, i.e. a reaction of oxidation of the aldehyde into a carboxylic acid, we find a ∆G0’=-10kcal (7.3kcal are equivalent to one ATP). The two-steps reaction is favoured because we can store the energy as ATP.
The same is true for the steps 8, 9, 10.

The two first steps cost energy but the third is very favourable. In total, we have a ∆G0’=-6kcal/mol and the formation of an ATP.
- Uncoupling agent
There are some molecules that can block the formation of the ATP. It is for instance the case of the arsenate ion which is a poison for us. In the step 6 and 7, the ion takes the place of an inorganic phosphate.

We still obtain the product of the step 7 but without the formation of ATP.
- energetic balance
The combustion of one glucose is an exothermic reaction:
![]()
The combustion of the products of the glycolysis (two pyruvates) gives
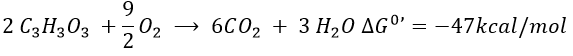
It is about 7% of the energy of one glucose. To that we can add the energy of the phosphoester bond of the 2ATP: 2×7.3kcal/mol.
It is still a very small quantity of energy that was recovered from the glucose. This method was used when there was almost no oxygen available and is used in anaerobic environments.
- Other monosaccharides can make the glycolysis after being transformed by enzymes into glucose or one intermediate of the glycolysis.
Chapitre 8 : Catabolisme du glucose – oxydation aérobie
Ce processus est couplé à la respiration cellulaire, implique O2 et est beaucoup plus efficace que l’oxydation anaérobie. Au lieu de 2 ATP, l’oxydation aérobie génère 38 ATP par le glucose. Il peut également oxyder les acides gras et les parties carbonatées des acides aminés.
Le cycle de Krebs: cycle de l’acide citrique
Szent Fuorgue a étudié la respiration cellulaire à partir d’un extrait de muscle. Il a analysé l’absorption d’O2 en présence de diverses molécules. Il a observé que certains d’entre eux augmentent considérablement l’absorption d’oxygène par les tissus. C’est le cas pour le succinate et le fumarate.
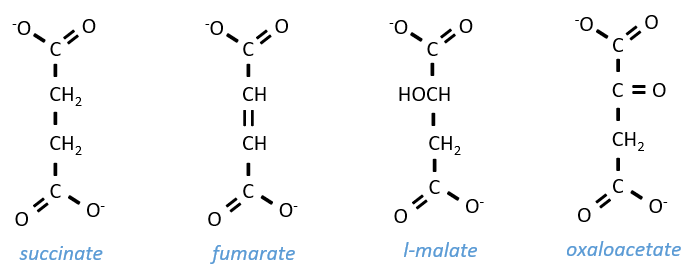
Ces molécules sont stables aux variations de la température. La combustion d’un succinate consomme normalement 3 O2 mais pendant les expériences, ils ont observé que l’absorption d’oxygène était au-dessus de cette valeur. Ils ont également montré que l’absorption peut être diminuée si l’on ajoute du malate au système. Le malate est un inhibiteur qui affecte l’oxaloacétate, un catalyseur du cycle de Krebs qui est régénéré à chaque cycle sauf en présence de malate.
Le cycle peut être repris par la figure suivante :
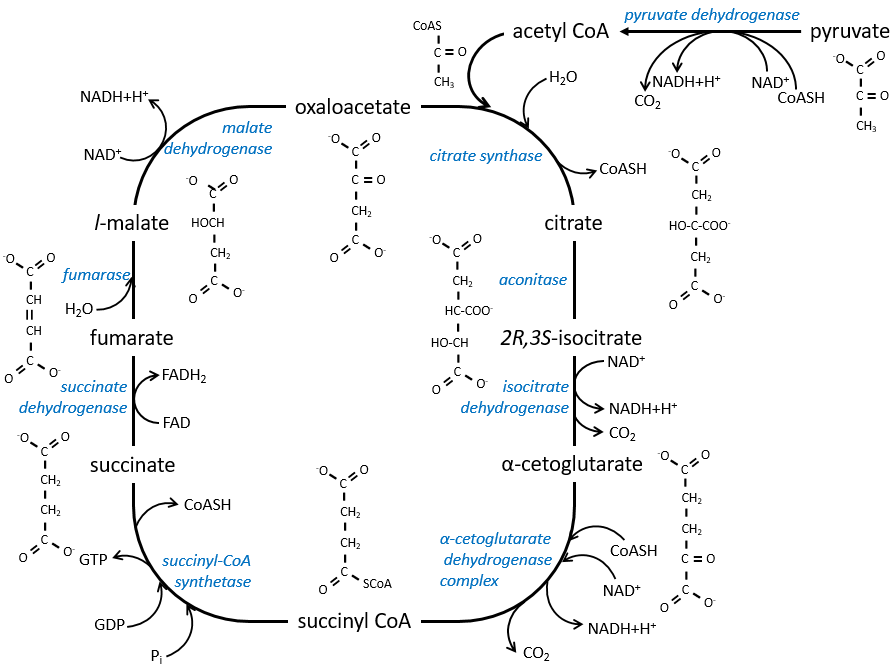
Le citrate est le produit de la première réaction du cycle. Avant d’expliquer le cycle, nous allons expliquer la formation de l’acétyl CoA. Il est fabriqué à partir de pyruvate. La première étape est la substitution d’un CO2 par le COASH par une liaison thioester.

La réaction est irréversible (libération de CO2) et est catalysée par une grande enzyme: la pyruvate déshydrogénase. À l’intérieur de l’enzyme, on trouve la vitamine B1. Simultanément, il y a une oxydation faite par le NAD +. Le produit est l’acétyl coenzyme A, ou l’acétyl-coA.
La première étape forme le citrate par la condensation entre l’acétyl-coA et l’oxaloacétate. La réaction est aidée par la citrate synthétase qui prend un proton du groupe méthyle de l’acétylCoA. Il libère la coenzyme qui peut être utilisée à nouveau.

Le citrate est symétrique mais il est considéré comme prochiral par l’enzyme de la réaction suivante. Pour poursuivre le cycle, l’aconitase change la conformation du citrate pour obtenir l’isocitrate.

L’équilibre est fortement en faveur de la gauche mais l’espèce droite est consommée par les réactions suivantes de sorte que la réaction est déplacée vers la droite. L’étape 3 est subdivisée en une réaction d’oxydation et une décarboxylation.
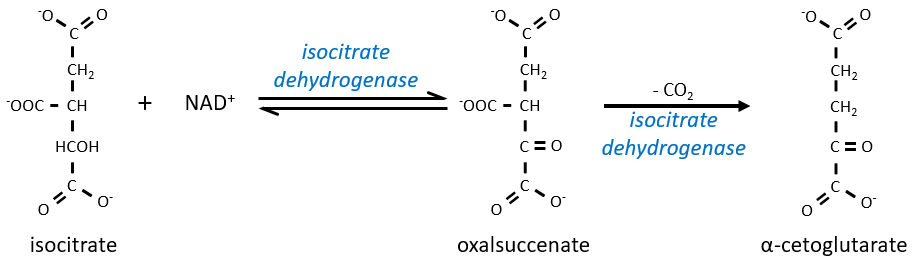
L’étape 4 est similaire à la formation de l’acétyl-CoA et conduit à la formation du succinyl-coA.

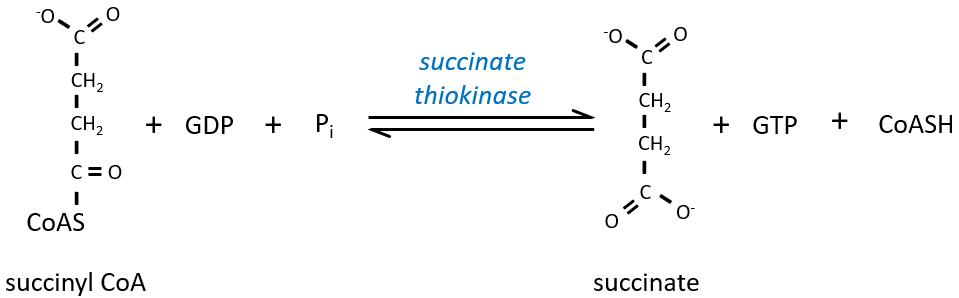
Le clivage de la liaison thioester fournit suffisamment d’énergie pour former, non pas un ATP mais un GTP.
Le succinate est ensuite oxydé pour le fumarate. Le cofacteur est le FAD: Flavin adénine dinucléotide, un dérivé de la riboflavine (vitamine B2).
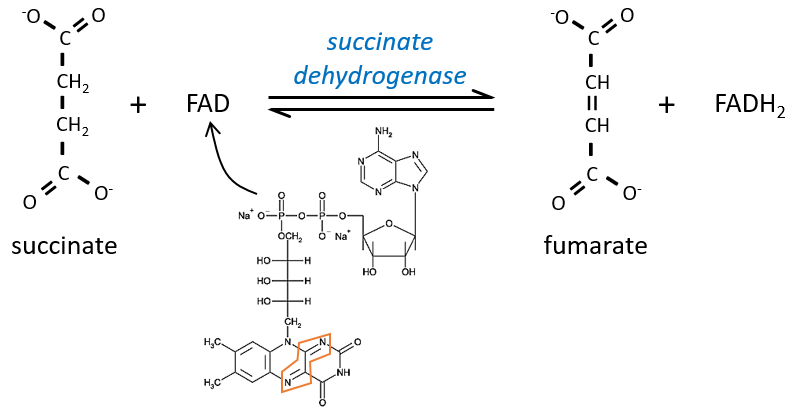
La réduction du FAD se fait dans la zone orange.
L’étape 7 nécessite une molécule d’eau pour former le malate. Le malate est une molécule chirale, la chiralité donnée par la structure du site actif de l’enzyme. En conséquence, seul le l-malate est obtenu.
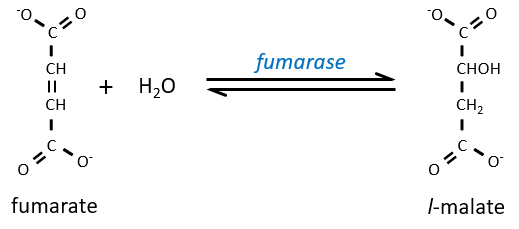
Enfin, l’oxaloacétate est régénéré à partir du malate.
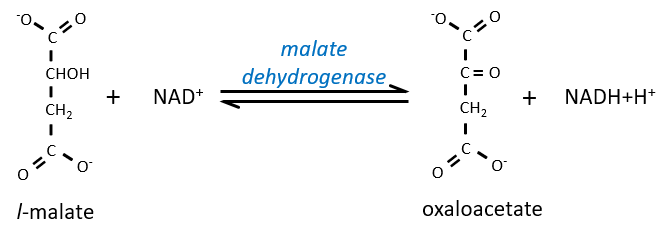
Maintenant, vous pouvez dire qu’il n’y a aucun des 38 ATP promis au début de la section. Un seul GTP a été formé pendant le cycle mais plusieurs CO2 ont été rejetés et 3 NAD + et un FAD ont été réduits. Ces molécules représentent l’énergie de l’ATP. En outre, c’est le processus qui se produit dans les cellules aérobies, mais aucun O2 n’a jamais été impliqué dans le cycle. Nous verrons la source de l’ATP dans la section suivante: la chaîne respiratoire.
Chapitre 9: Catabolisme du glucose – chaîne respiratoire
En 1935, Engelhardt a analysé le taux d’ATP dans les globules rouges en fonction du taux d’oxygène. Les expériences ont montré que l’ATP augmente avec la quantité d’O2. Contrairement à la levure, les cellules sanguines devaient être en une seule pièce pour observer le phénomène. Plus encore, certaines enzymes contenues dans un extrait de cellules sanguines détruisent l’ATP. Plus tard, Kalkar a montré que si nous ajoutons une enzyme à l’extrait, le ratio d’ATP augmente en présence d’oxygène.
Keilin (1925) étudiait les moustiques responsables du paludisme. Avec un spectromicroscope, il a regardé les pattes d’un moustique et a vu qu’elles changeaient de couleur. Au repos les muscles s’oxydent mais quand ils sont excités les muscles consomment l’oxygène et sont donc moins oxydés. La couleur est donnée par le cytochrome, une molécule qui change de couleur en fonction de l’oxydation.
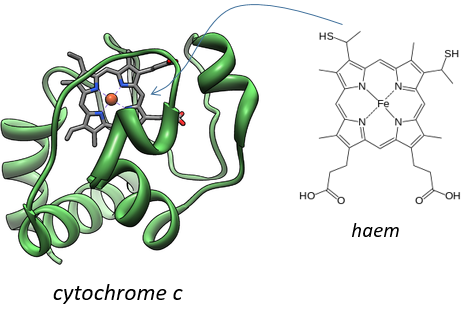
Cette molécule appartient à la mitochondrie. La mitochondrie est une sorte de bactérie hébergée par les eucaryotes.
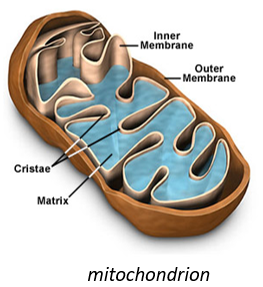
Ils ont leur propre membrane, composée d’une membrane interne et d’une membrane externe poreuse. La matrice est à l’intérieur de la membrane interne et l’espace intermembranaire est également appelé cristae où la membrane est en saillie. De même que l’hémoglobine, le cytochrome est une protéine qui possède une hème dont le fer peut changer d’état d’oxydation. Cette propriété est utilisée dans la chaîne respiratoire. Le cytochrome appartient à la membrane interne de la mitochondrie le long de laquelle il peut se déplacer et il sépare la glycolyse du cycle de l’acide citrique. Le cycle de l’acide citrique se déroule dans la matrice de la mitochondrie tandis que la glycolyse se déroule à l’extérieur de la mitochondrie.
Chaîne respiratoire :
La chaîne respiratoire peut être résumée par la figure et le tableau suivants:
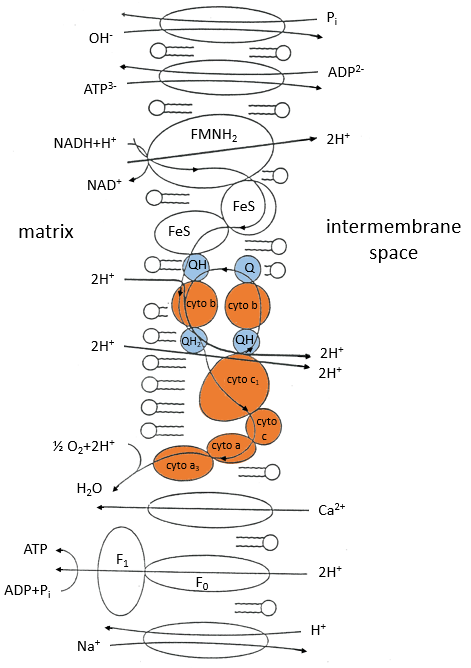
Dans la membrane interne nous trouvons 4 complexes – NADH-ubiquinone réductase, succinate-ubiquinone réductase, ubiquinol-cytochrome c réductase et cytochrome oxydase – qui font des réactions redox et transfèrent des électrons d’un côté de la membrane à l’autre (parfois des protons au lieu des électrons). Une réaction d’un côté de la membrane (matrice ou espace inter-membranaire) est toujours couplée à une réaction de l’autre côté de la membrane. Une réaction de réduction est couplée à une réduction de l’oxydation et vice-versa. Tout le phénomène implique des transferts d’électrons à l’intérieur de la membrane et des transferts de protons d’un côté de la membrane à l’autre. Notez que certains complexes appartiennent à la membrane mais ne font face qu’à l’un de ses côtés.
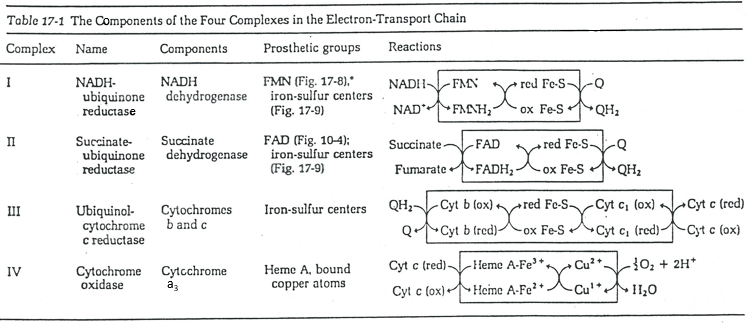
Q est l’ubiquinone, un cofacteur qui appartient à la membrane. Il interagit avec le cytochrome c dans une boucle d’oxydoréduction. On peut voir que l’oxygène est impliqué par le complexe IV. Pour reprendre la boucle, on peut écrire deux réactions d’oxydoréduction, l’une avec le NAD et l’autre avec le FAD.
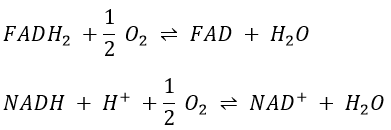
Cependant O2 ne peut pas interagir directement avec FADH2 et NADH+H+ et cette boucle est donc nécessaire. Pour redox, l’énergie libre de Gibbs est :
![]()
Pour déterminer la différence de potentiel ΔE °, nous regardons les couples impliqués dans la réaction:
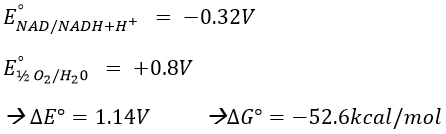
Pour FAD, nous avons 43.3 kcal/mol. Il y a un transfert de protons impliqué dans le processus mais il doit y avoir un équilibre entre les concentrations de charge à l’intérieur de la cellule et à l’extérieur de la cellule. Les protons peuvent sortir de la matrice de la mitochondrie à travers des complexes protéiques qui génèrent de l’ATP à partir du flux de protons (en bas de la figure) La protéine F1-ATPase est composée de deux parties, F0 dans la membrane et F1 dans la matrice de la mitochondrie. F0 pompe les protons de l’espace intermembranaire vers la matrice. F1 reçoit l’énergie du transport et transforme l’ADP en ATP. Ces espèces sont chargées négativement et nécessitent un transport à travers la membrane (haut de la figure). Un ADP ne peut entrer dans la matrice que si un ATP sort de la matrice. Les phosphates inorganiques Pi sont également transportés à travers la membrane. L’énergie pour former l’ATP provient du gradient de pH. Il génère une force motrice protonique.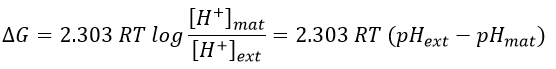
Où les indices mat et ext sont respectivement matrice et son extérieur (l’espace intermembrane). Le gradient de pH génère une différence de potentiel électrique ΔV.
![]()
En combinant les deux effets, nous avons
![]()
En divisant cette expression par nF, on obtient l’expression d’une variation de l’énergie libre Δp associée au transfert d’une mole de protons (en volt).
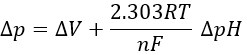
Le coefficient 2,303RT / nF du gradient de pH a une valeur de 59 mV à 25 ° C.
![]()
On peut mesurer le pH et la différence de potentiel: ΔV = 0.14V et ΔpH = -1.4.
![]()
Cela correspond à une variation d’énergie libre égale à :
![]()
Pour former une mole d’ATP, nous avons besoin de 7,3 kcal. Dans la chaîne respiratoire, il y a 4 complexes qui oxydent le NADH et le FAD. Ils forment respectivement l’équivalent de 11 et 8 protons par boucle.

Nous pouvons écrire une équation globale de la « combustion » d’un pyruvate au cours du cycle de l’acide citrique et de la chaîne respiratoire: Pour résumer, l’oxydation d’un NADH génère ~ 3 ATP et l’oxydation de FAD génère ~ 2ATP.
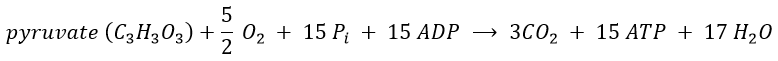
Les 15 ATP viennent de
4 NADH (un avant le cycle de l’acide citrique et 3 pendant le cycle) : 12ATP,
de 1 FADH2 : 2ATP
et à partir de 1 GTP :1 ATP.
Pour former un pyruvate, la glycolyse forme 2 ATP et utilise 2 NAD qui sont réduits en NADH + H +.
![]()
Donc en considérant 3 ATP par NADH, cela correspond à la production de 8 ATP. Ajouté au 15 ATP de chaque pyruvate (x2), on obtient 38ATP par glucose. Par rapport à la combustion du glucose (ΔG ° ‘= – 686kcal / mol), il représente environ 40% de l’énergie potentielle (38×7.3kcal / mol = 277kcal / mol).
Le NAD impliqué dans la glycolyse et qui produit un NADH n’est pas au même endroit (cytosol) que le NADH requis dans la respiration cellulaire (matrice de la mitochondrie). Le NADH ne peut entrer librement dans la mitochondrie parce qu’il est chargé. Il existe un système de navette qui peut différer pour différentes cellules et qui va modifier le NADH pour permettre son passage à travers la membrane, puis le modifier à nouveau pour qu’il puisse y être utilisé. Dans le cerveau et dans les muscles, c’est une navette de glycophosphate que nous allons expliquer. La navette est fondamentalement composée de deux réactions: une dans le cytosol et une dans la matrice de la mitochondrie:
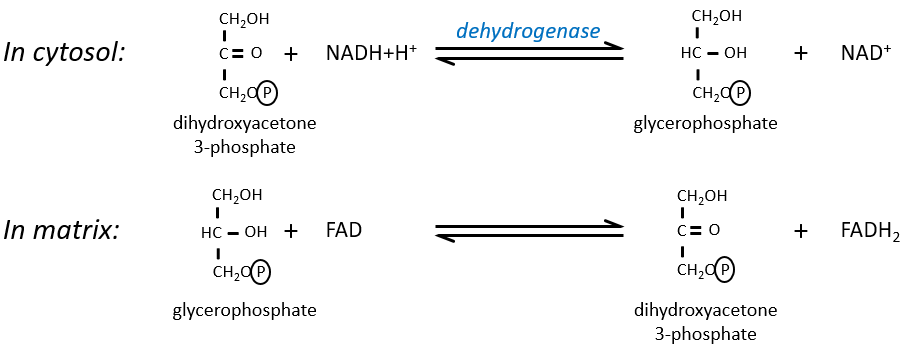
La navette peut être représentée comme comme ceci :
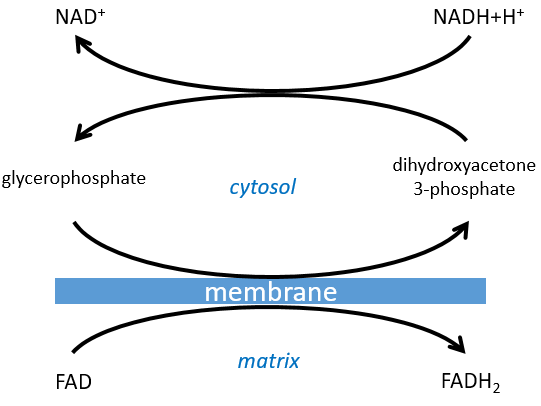
Si vous vous souvenez, la dihydroxyacétone-3P faisait partie de la glycolyse (rectangle rouge sur la figure suivante): c’est l’un des deux trioses phosphates produits à partir du fructose -1,6-diphosphate. Le fait que ce triose soit impliqué dans la navette ne diminue pas significativement le rendement de la glycolyse: la cellule a besoin d’une quantité donnée de dihydroxyacétone pour la navette mais les molécules sont régénérées dans la matrice des mitochondries et peuvent alors retourner au cytosol. Donc, ils doivent juste être produits une fois. Le reste de la production est transformé en glycéraldéhyde 3P pour la glycolyse.
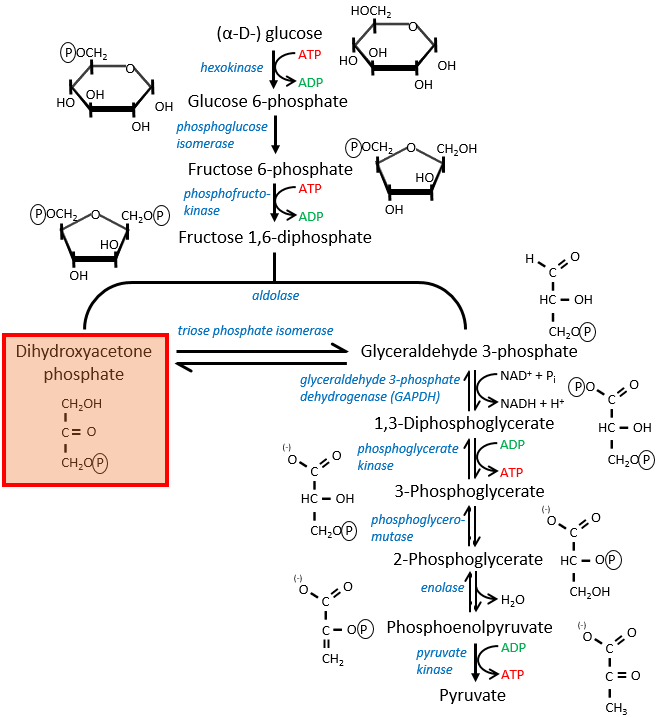
Le FADH2 est oxydé pendant la respiration et la dihydroxyacétone peut revenir au cytosol. La navette a un faible coût: elle oxyde un NADH en NAD dans le cytosol alors que la réaction dans la matrice implique FAD / FADH2. En terme d’énergie, il représente un ATP utilisé car tous les processus ne se déroulent pas au même endroit.
La navette malate-aspartate :
Les mêmes cofacteurs (NADH+H+/NAD+) sont utilisés donc le rendement ne change pas avec cette navette (ATP 38). Le mécanisme est basé sur le pouvoir réducteur de l’oxaloacétate.
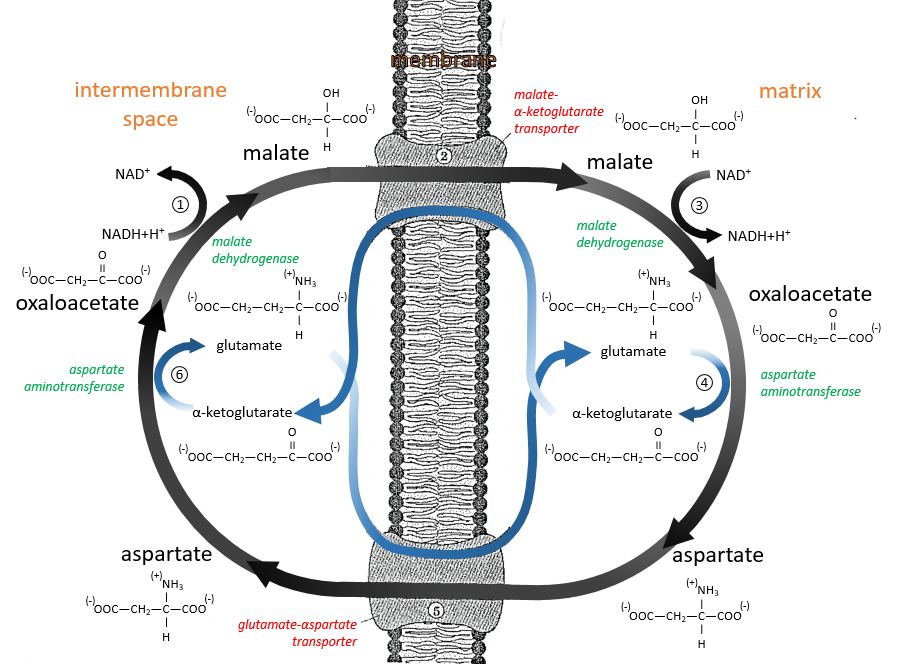
Réduit en malate (1), il est transporté dans la matrice de la mitochondrie (2) à travers le transporteur malate-α-cétoglutarate si un α-cétoglutarate est disponible pour effectuer le déplacement dans la direction opposée. La réaction inverse, l’oxydation du malate en oxaloacétate est faite dans la matrice (3). Pourtant, l’oxaloacétate ne peut pas sortir de la membrane. Pour ce faire, il est transformé en un acide aminé, l’aspartate, par une réaction de transamination (4):
![]()
Il est fait ici par l’aspartate transaminase avec l’utilisation du glutamate comme acide aminé. En conséquence, l’oxaloacétate est transformé en aspartate qui peut se déplacer à travers la membrane à travers un transporteur nécessitant le passage dans la direction opposée d’un glutamate (5). Dans le cytosol, il est retourné dans l’oxaloacétate avec exactement la même réaction (6) que de l’autre côté de la membrane.
Chapter 10 : Biosynthèse du cholestérol, des stéroïdes et des isoprénoïdes
Le cholestérol est sans doute le lipide le plus médiatisé en raison de la forte corrélation entre les taux élevés de cholestérol dans le sang et l’incidence des maladies cardiovasculaires chez l’homme . Moins bien connu est le rôle important du cholestérol en tant que composant des membranes cellulaires et en tant que précurseur des hormones stéroïdiennes et des acides biliaires. Le cholestérol est une molécule essentielle chez de nombreux animaux, y compris les humains, mais il n’est pas requis dans le régime des mammifères – toutes les cellules peuvent le synthétiser à partir de simples précurseurs. La structure de ce composé à 27 atomes de carbone suggère une voie de biosynthèse complexe, mais tous les atomes de carbone sont fournis par un seul précurseur (l’acétate)
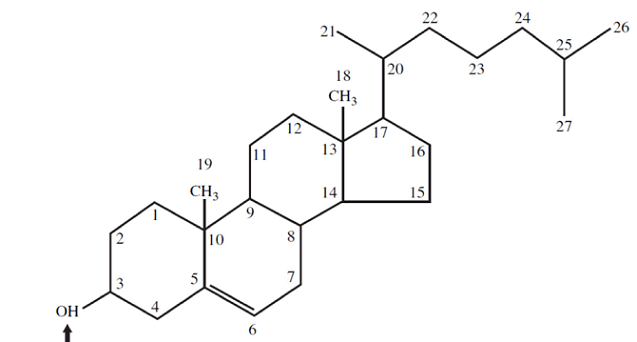
Les unités d’isoprène qui sont les intermédiaires essentiels dans la voie de l’acétate au cholestérol, sont également des précurseurs de nombreux autres lipides naturels et les mécanismes par lesquels les unités d’isoprène sont polymérisées sont similaires dans toutes ces voies. Nous commencerons par des étapes principales dans la biosynthèse du cholestérol à partir de l’acétate, puis étudierons les voies de biosynthèse de certains des nombreux composés dérivés des unités d’isoprène, qui partagent des étapes précoces avec la voie vers le cholestérol, illustrant l’extraordinaire polyvalence des condensations isoprénoïdes dans la biosynthèse. Le cholestérol est fabriqué à partir d’acétyl-CoA en quatre étapes, comme les acides gras à longue chaîne le cholestérol est fabriqué à partir d’acétyl-CoA, mais le plan d’assemblage est trèsdifférent. Dans les premières expériences, les animaux ont été nourris avec de l’acétate marqué au 14C soit dans le carbone méthylique, soit dans le carbone carboxyle. Le profil de marquage dans le cholestérol isolé des deux groupes d’animaux a fourni le plan d’élaboration des étapes enzymatiques de la biosynthèse du cholestérol. La synthèse se déroule en quatre étapes,
1) la condensation de trois unités d’acétate pour former un intermédiaire à six atomes de carbone, le mévalonate:
La synthèse du Mévalonate à partir de l’Acétate La première étape de la biosynthèse du cholestérol conduit au mévalonate. Deux molécules d’acétyl-CoA se condensent pour former de l’acétoacétyl-CoA, qui se condense avec une troisième molécule d’acétyl-CoA pour donner le composé à six carbones 3-hydroxy-3-méthylglutaryl-CoA (HMG-CoA). Ces deux premières réactions sont catalysées par la thiolase et la HMG-CoA synthase, respectivement. La HMG-CoA synthase cytosolique dans cette voie est distincte de l’isoenzyme mitochondriale qui catalyse la synthèse de l’HMG-CoA dans la formation de corps cétoniques. La troisième réaction est l’engagement et la limitation des taux étape: réduction de l’HMG-CoA en mévalonate, pour lequel chacune des deux molécules de NADPH donne deux électrons. HMG-CoA réductase, une protéine membranaire intégrale du réticulum endoplasmique lisse, est le point majeur de la régulation sur la voie vers le cholestérol ( mode d’action des statines), comme nous le verrons.
2 conversion du mévalonate en unités d’isoprène activé:
La conversion du maléate en deux isoprènes activés Dans l’étape suivante de la synthèse du cholestérol, trois groupes phosphate sont transférés de trois molécules d’ATP au mévalonate (figures 21-35). Le phosphate attaché au groupe hydroxyle C-3 du mévalonate dans le 3-phospho-5-pyrophosphomevalonate intermédiaire est un bon groupe partant; à l’étape suivante, à la fois cette phosphate et le groupe carboxyle voisin partent, produisant une double liaison dans le produit à cinq atomes de carbone, le 3-isopentényl pyrophosphate. C’est le premier des deux isoprènes activés au centre de la formation du cholestérol. L’isomérisation du ß-3-isopentényl pyrophosphate donne le second isoprène activé, le diméthylallyl pyrophosphate. La synthèse de l’isopentényl pyrophosphate dans le cytoplasme des cellules végétales suit la voie décrite ici. Cependant, les chloroplastes végétaux et de nombreuses bactéries utilisent une voie indépendante du mévalonate. Cette voie alternative ne se produit pas chez les animaux, c’est donc une cible intéressante pour le développement de nouveaux antibiotiques.
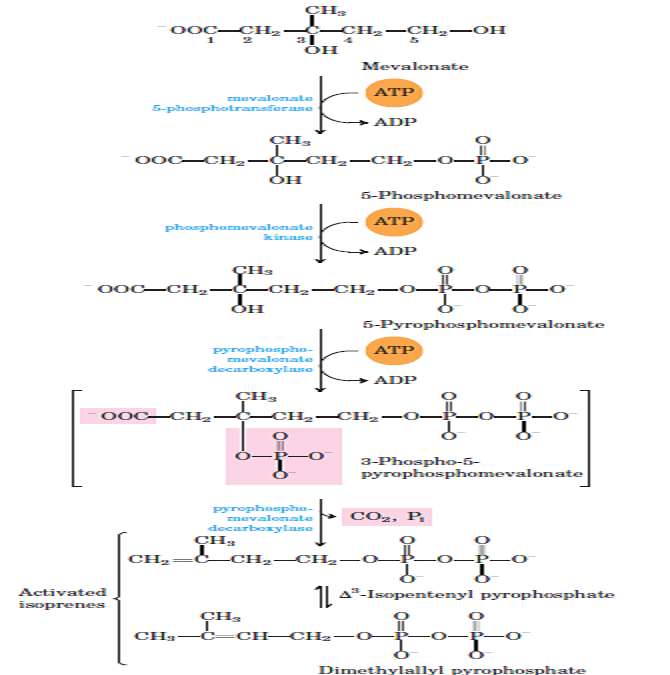
3 polymérisation de six unités d’isoprène à 5 atomes de carbone pour former le squalène linéaire à 30 atomes de carbone :
La condensation de six unités d’isoprènes activées pour former le squalène. L’isopentényl pyrophosphate et le diméthylallyl pyrophosphate subissent une condensation de tête à queue, dans laquelle un groupe pyrophosphate est déplacé et une chaîne de 10 carbones, le géranyl pyrophosphate, est formée . (Fig ci-dessous) . (La «tête» est l’extrémité à laquelle le pyrophosphate est joint.) Le pyrophosphate de géranyle subit une autre condensation de tête à queue avec l’isopentényl pyrophosphate, donnant le farnésyl pyrophosphate, intermédiaire à 15 atomes de carbone. Enfin, deux molécules de farnésyl pyrophosphate se joignent tête à tête, avec élimination des deux groupes pyrophosphates, pour former le squalène. Les noms communs de ces intermédiaires dérivent des sources d’où ils ont été isolés pour la première fois. Le géraniol, est un composant de l’huile de rose, a l’arôme des géraniums, et le farnesol est un composé aromatique trouvé dans les fleurs de l’acacia Farnese. De nombreux parfums naturels d’origine végétale sont synthétisés à partir d’unités d’isoprène. Le squalène, isolé pour la première fois du foie des requins (genre Squalus),contient 30 atomes de carbone, 24 dans la chaîne principale et 6 sous forme des groupes méthyles.
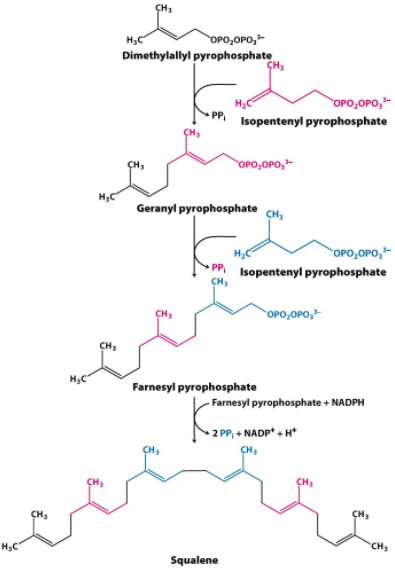
4 la cyclisation du squalène pour former les quatre anneaux du noyau stéroïdien, avec une autre série de changements (oxydations, élimination ou migration des groupes méthyle) pour produire du cholestérol.
Lorsque la molécule de squalène est représentée comme sur la figure ci dessous, la relation de sa structure linéaire avec la structure cyclique des stérols devient apparente. Tous les stérols ont les quatre anneaux fusionnés qui forment le noyau stéroïde, et tous sont des alcools, avec un groupe hydroxyle sur C-3 – d’où le nom « sterol ». L’action du squalène monooxygénase ajoute un atome d’oxygène à la fin de la chaîne de squalène ( atome d’oxygène provenant de O2), formant un époxyde. Cette enzyme est une autre oxydase à fonction mixte , Le NADPH réduit l’autre atome d’oxygène de O2 en H2O. Les doubles liaisons du produit, squalène Le 2,3-époxyde est positionné de sorte qu’une réaction concertée remarquable peut convertir l’époxyde de squalène linéaire en une structure cyclique. Dans les cellules animales, cette cyclisation entraîne la formation de lanostérol, qui contient les quatre anneaux caractéristiques du noyau stéroïdien. Lanostérol est finalement converti en cholestérol dans une série d’environ 20 réactions qui comprennent la migration de certains groupes méthyle et l’élimination des autres. L’élucidation de cette voie biosynthétique extraordinaire, l’une des plus complexes connues, a été réalisée par Konrad Bloch, Feodor Lynen, John Cornforth et George Popják à la fin des années 1950. Le cholestérol est la caractéristique des stérols des cellules animales; les plantes, les champignons et les protistes produisent d’autres stérols étroitement apparentés. Ils utilisent la même voie de synthèse jusqu’au squalène 2,3-époxyde, point auquel les voies divergent légèrement, produisant d’autres stérols, tels que le stigmastérol dans de nombreuses plantes et l’ergostérol dans les champignons.
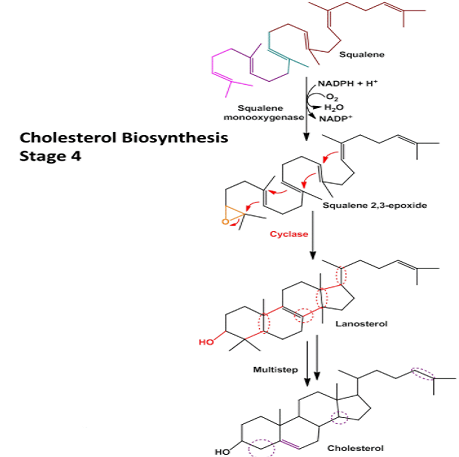
Le cholestérol a plusieurs destins :
Une grande partie de la synthèse du cholestérol chez les vertébrés a lieu dans le foie. Une petite fraction du cholestérol qui s’y trouve est incorporée dans les membranes des hépatocytes, mais la plus grande partie est exportée sous l’une des trois formes suivantes: cholestérol biliaire, acides biliaires ou esters de cholestérol. Les acides biliaires et leurs sels sont des dérivés du cholestérol relativement hydrophiles qui sont synthétisés dans le foie et facilitent la digestion des lipides. Les esters de cholestérol sont formés dans le foie par l’action de l’acyl-CoA-cholestérol acyltransférase (ACAT). Cette enzyme catalyse le transfert d’un acide gras de la coenzyme A vers le groupe hydroxyle du cholestérol, convertissant le cholestérol en une forme plus hydrophobe. Les esters de cholestérol sont transportés dans des particules de lipoprotéines sécrétées vers d’autres tissus qui utilisent du cholestérol, ou ils sont stockés dans le foie. Tous les tissus animaux en croissance ont besoin de cholestérol pour la synthèse membranaire, et certains organes (la glande surrénale et les gonades, par exemple) utilisent le cholestérol comme précurseur de la production d’hormones stéroïdiennes (nous en discuterons plus loin). Le cholestérol est également un précurseur de la vitamine D.